
Khi các mô hình ngôn ngữ lớn (LLMs) tiếp tục định hình lại cách các ứng dụng hiện đại được xây dựng — từ AI Copilot cho đến hệ thống chatbot doanh nghiệp — nhu cầu về một kiến trúc hạ tầng và quy trình vận hành bài bản ngày càng trở nên cấp thiết. Chính từ đó, một lĩnh vực mới mang tên LLMOps đã ra đời.
Tương tự như cách MLOps giúp tiêu chuẩn hóa quy trình triển khai các mô hình machine learning truyền thống, LLMOps tập trung giải quyết những thách thức vận hành đặc thù khi làm việc với foundation models quy mô lớn.
Quan trọng hơn, LLMOps không chỉ đơn thuần là đưa mô hình lên API để inference. Nó bao gồm toàn bộ vòng đời phát triển, từ kỹ thuật xây dựng prompt, fine-tuning mô hình, áp dụng phương pháp RAG (retrieval-augmented generation), quản lý phiên bản, giám sát hiệu suất, tối ưu chi phí, đến đảm bảo truy cập bảo mật.
Vì kích thước và độ phức tạp của LLMs rất lớn, nên một kiến trúc chuyên biệt là cần thiết để đảm bảo tính ổn định, khả năng mở rộng và dễ bảo trì trong môi trường production.
Vậy LLMOps kiến trúc thực sự gồm những gì? Làm thế nào để quản lý và triển khai hiệu quả các mô hình LLM trong môi trường production? Hãy cùng HBLAB tìm hiểu trong bài viết dưới đây.
1. LLMOps là gì?
LLMOps đề cập đến thiết kế có cấu trúc và tập hợp các thành phần cần thiết để quản lý toàn bộ vòng đời của các mô hình ngôn ngữ lớn (LLMs) trong môi trường sản xuất. Đây là nền tảng cho phép các nhóm kỹ thuật chuyển từ giai đoạn thử nghiệm sang xây dựng những ứng dụng thực tiễn, có khả năng mở rộng, bảo mật và dễ bảo trì với sức mạnh của LLM.
Khác với kiến trúc MLOps truyền thống – vốn tập trung vào dữ liệu có cấu trúc và pipeline huấn luyện mô hình – LLMOps phải xử lý những thách thức riêng biệt như:
- Dàn dựng prompt (prompt orchestration)
- Triển khai Retrieval-Augmented Generation (RAG)
- Quản lý phiên bản mô hình ở quy mô lớn
- Đảm bảo độ trễ suy luận (inference latency) theo thời gian thực
- Điều phối nhiều mô hình cùng lúc (multi-model routing)
- Quản lý truy cập bảo mật cho nhiều nhóm người dùng
Kiến trúc LLMOps tích hợp hạ tầng, tự động hóa và khả năng quan sát (observability) để đảm bảo khả năng triển khai đáng tin cậy và quản trị hiệu quả. Một hệ thống đầy đủ thường bao gồm:
- Môi trường huấn luyện và suy luận (fine-tuning & inference)
- Cơ sở dữ liệu vector và pipeline tìm kiếm thông tin
- Template prompt và lớp điều phối
- Hệ thống giám sát, ghi log và vòng phản hồi hành vi mô hình
Kiến trúc này hỗ trợ cả các mô hình đã được huấn luyện sẵn (served via API) lẫn mô hình được fine-tune và triển khai trong môi trường riêng tư. Khi LLM ngày càng được ứng dụng rộng rãi trong nhiều ngành, việc xây dựng một kiến trúc bài bản là điều tất yếu để đảm bảo tốc độ phát triển, tối ưu chi phí và xây dựng niềm tin từ người dùng.
Hiểu rõ kiến trúc LLMOps sẽ giúp các đội ngũ kỹ thuật thiết kế hệ thống vừa linh hoạt, vừa có thể mở rộng mà vẫn tuân thủ các yêu cầu bảo mật, pháp lý và mục tiêu kinh doanh thực tế.
2. Các thành phần chính trong kiến trúc LLMOps
2.1. Quản lý dữ liệu (Data Management)
Xử lý dữ liệu thô: làm sạch, phân loại và tạo embedding để phục vụ RAG. Cần kiểm soát phiên bản dữ liệu và theo dõi nguồn gốc (lineage) cho việc truy xuất và audit
2.2. Phát triển mô hình (Model Development)
Chọn mô hình nền tảng như GPT, LLaMA, Falcon và điều chỉnh thông qua fine‑tuning hoặc prompt engineering. Các kỹ thuật như LoRA, PEFT giúp tiết kiệm tài nguyên khi cập nhật mô hình
2.3. Triển khai & Phục vụ (Inference & Deployment)
Cung cấp API phục vụ mô hình có khả năng scaling, batching, quantization, streaming token, caching, và tối ưu độ trễ. Hỗ trợ rollback, A/B testing và routing nhiều mô hình
2.4. Bảo mật và Tuân thủ (Security & Compliance)
Áp dụng mã hóa, kiểm soát truy cập (RBAC), ẩn danh dữ liệu và audit trail để tuân thủ tiêu chuẩn như HIPAA, GDPR hoặc SOC 2
2.5. Quản trị & Trách nhiệm AI (Governance & Responsible AI)
Theo dõi prompt versioning, kiểm soát hallucination, phát hiện bias, lọc nội dung có hại và lưu log mọi tương tác để đảm bảo hoạt động có đạo đức và minh bạch
3. Quy trình triển khai LLM
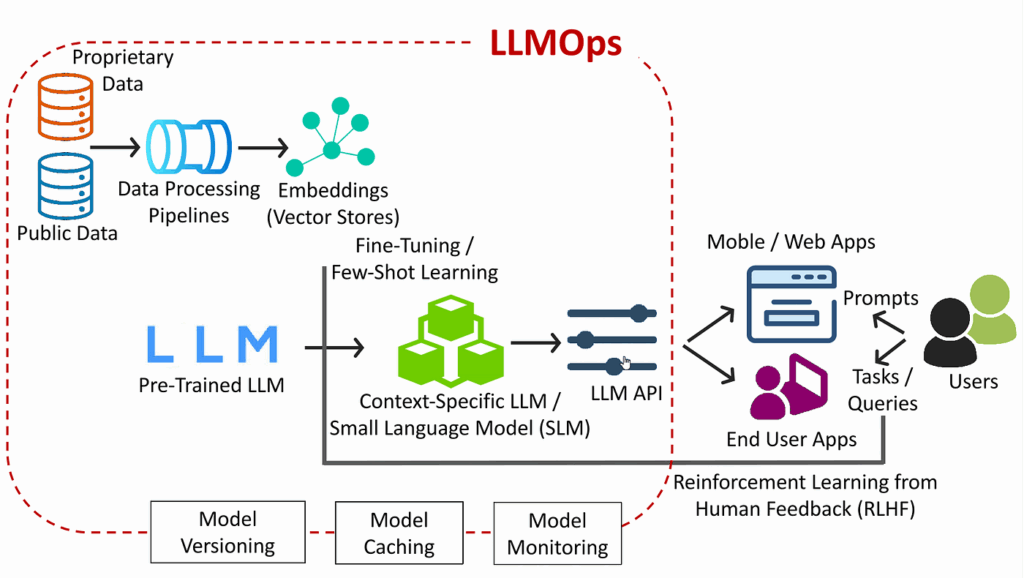
Quy trình triển khai LLM từ đầu đến cuối:
- Thu thập dữ liệu: Từ văn bản công khai hoặc nội bộ → xử lý & chuyển thành embedding → lưu vào vector database.
- Lựa chọn mô hình: Chọn LLM pre-trained → fine-tune theo ngữ cảnh doanh nghiệp.
- LLM Gateway: Là API trung tâm kiểm soát routing, batching, template prompt, thu thập số liệu truy vấn.
- LLM API Serving: Tối ưu hóa phản hồi thời gian thực, giảm độ trễ, hỗ trợ caching và theo dõi hiệu suất.
- Ứng dụng người dùng & Feedback: Ứng dụng gửi prompt → nhận phản hồi từ mô hình → dữ liệu phản hồi dùng cho RLHF hoặc retraining.
- Governance: Quản lý version, prompt, truy cập và đảm bảo tái sử dụng & kiểm soát.
4. Mô hình triển khai phổ biến trong thực tế
| Mô hình | Mô tả |
| API-Centric | Đơn giản, dễ triển khai. Mô hình LLM được truy cập qua REST API. Phù hợp tạo nội dung, tóm tắt, chatbot cơ bản. |
| RAG (Retrieval-Augmented Generation) | Kết hợp LLM với vector database để truy xuất thông tin ngữ cảnh, tăng độ chính xác. Thích hợp cho phân tích văn bản pháp lý, CSKH. |
| Workflow-Orchestration | Dùng LangChain, Airflow để kết nối nhiều bước như retrieval → inference → xử lý. Áp dụng cho AI agent hoặc multi-turn chatbot. |
| Fine-Tuned Private LLM | LLM được fine-tune & triển khai nội bộ, đảm bảo dữ liệu bảo mật. Phổ biến trong y tế, ngân hàng, quốc phòng. |
| Hybrid Cloud-Edge | Mô hình chính đặt cloud, logic nhẹ xử lý ở thiết bị edge. Giảm độ trễ, tiết kiệm băng thông. Phù hợp với IoT, xe tự hành, mobile. |
5. Các lớp công cụ trong hệ sinh thái LLMOps
| Lớp | Vai trò |
| Data & Embedding | Làm sạch, chunking, embedding, lưu trữ vector cho RAG |
| Model Serving | Tối ưu hóa inference, autoscaling, theo dõi latency, hỗ trợ 250+ LLM |
| Prompt & Orchestration | Quản lý template prompt, agent flows, multi-step orchestration |
| Monitoring & Governance | Giám sát drift, hallucination, chi phí token, log & audit trail |
| Workflow & Automation | CI/CD, retraining tự động, versioning mô hình |
