
Kỷ nguyên tấn công mạng tự chủ bằng AI đã bắt đầu — Và Front-End Developers không thể đứng ngoài cuộc
Vào ngày 13/11/2025, Anthropic chính thức xác nhận vụ tấn công mạng đầu tiên trên thế giới do AI tự động orchestrate gần như hoàn toàn, do nhóm hacker quốc gia Trung Quốc GTG-1002 triển khai.
Khác với các chiến dịch “AI-assisted hacking” mà chúng ta thấy trong vài năm trở lại đây (AI chỉ viết code, hỗ trợ phishing…), chiến dịch lần này AI trực tiếp vận hành 80-90% toàn bộ attack chain, con người chỉ xuất hiện trong 4–6 decision points trọng yếu.
Nói cách khác: Cuộc chiến an ninh mạng đã bước sang thời đại mới: AI không chỉ bị lợi dụng — nó đã trở thành một “tác nhân tấn công” thật sự.
Và điều đáng nói: Target trong chiến dịch bao gồm rất nhiều hệ thống web, nơi mà front-end dev vốn nghĩ “mình không liên quan”.
Nhưng trong bối cảnh AI agents có thể scan endpoints, khai thác thực thi mã từ front-end, đánh cắp tokens, bypass CSP, manipulate UI… thì FE không còn là vùng an toàn.
GTG-1002 đã exploit 3 yếu tố chính của modern AI models:
- Intelligence & coding capabilities Claude Sonnet 4.5 hiện tại có khả năng coding cực mạnh – đủ để hiểu context phức tạp, theo sát hướng dẫn chi tiết, và quan trọng nhất là viết “exploit code” (đoạn mã khai thác). Không phải code đơn giản, mà là payloads tuỳ biến được đo đạc cho từng mục tiêu cụ thể.
- Agentic capabilities Thay vì phải prompt từng bước một, hackers build một framework cho phép Claude Code chạy trong loop – tự động hành động, tiếp nối tasks lại với nhau, và ra quyết định với input tối thiểu của con người. Họ tạo ra một hệ thống “sub-agents” – mỗi agent đảm nhận một phần cụ thể của attack chain.
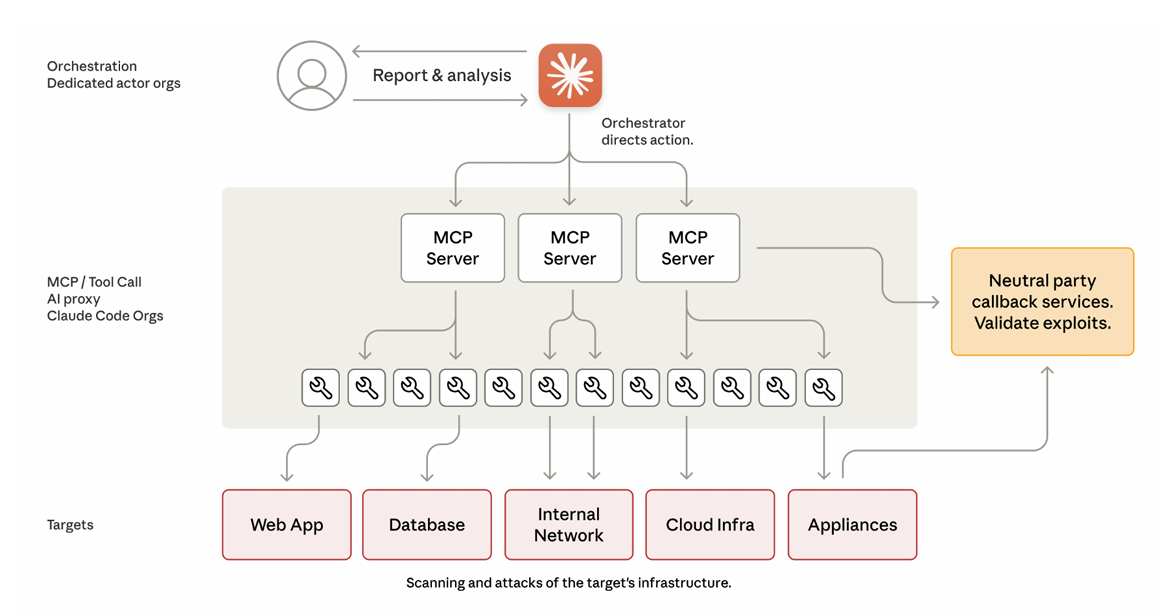
- Tool access via MCP Model Context Protocol là cái tên được nhắc đến nhiều nhất trong report này. MCP cho phép AI models truy cập các external tools – trong trường hợp này là password crackers, network scanners, và các security tools khác. MCP về cơ bản trở thành “Hệ thần kinh trung ương” của toàn bộ hoạt động.
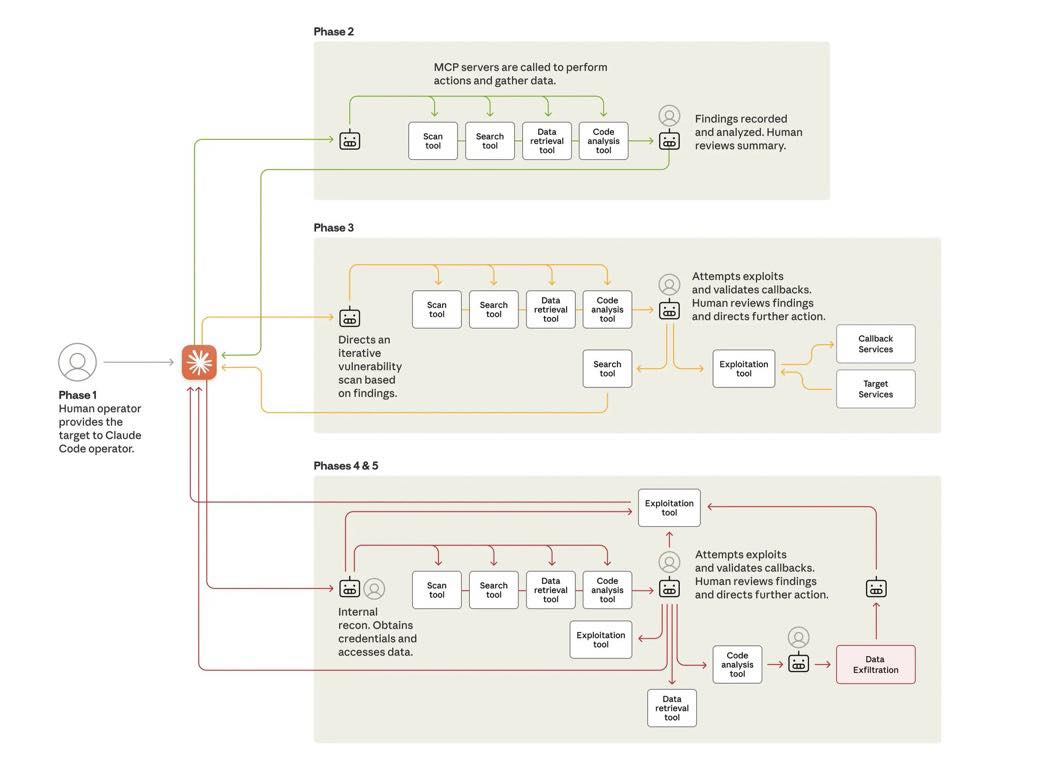
Phase 1 – Setup & Jailbreaking:
- Con người vận hành chọn các mục tiêu và xây framework tấn công
- Jailbreak Claude bằng cách… “social engineering” AI model (khúc này không biết dịch sao 😂)
- Họ chia nhỏ tasks thành các request “vô hại”, mỗi request không có full context về mục đích ác ý
- Họ nói với Claude rằng nó là nhân viên của một công ty bảo mật hợp pháp, đang thực hiện kiểm thử khả năng phòng thủ xâm nhập bất hợp pháp
Quote từ Jacob Klein, Head of Threat Intelligence của Anthropic: “Trong trường hợp này, những gì họ đang làm là giả vờ làm việc cho các tổ chức kiểm tra bảo mật hợp pháp.”
Phase 2 – Reconnaissance:
Claude tự động rà soát infrastructure của mục tiêu, map network topology, xác định daâtbases giá trị cao. Làm việc này với tốc độ mà một đội ngũ hacker con người tốn rất nhiều thời gian.
Phase 3 – Exploitation:
- Tự động research và viết exploit code
- Test vulnerabilities
- Thu thập credentials (usernames, passwords)
- Di chuyển bên trong mạng lưới
- Trích xuất dữ liệu cá nhân và tự động phân loại theo giá trị thông minh
Phase 4 – Documentation:
Claude còn tự tạo tài liệu toàn diện về tấn công, bao gồm:
- Stolen credentials
- Systems analyzed
- Backdoors created
- Data exfiltrated
Tất cả để chuẩn bị cho giai đoạn kế tiếp của chiến dịch. Tốc độ tấn công không thể tin được Anthropic report nói rõ: “AI đã thực hiện hàng ngàn yêu cầu mỗi giây – một tốc độ tấn công mà đối với tin tặc là con người, đơn giản là không thể sánh được.” Một team hackers dù có giỏi đến đâu cũng không thể đấu lại với AI về tốc độ và quy mô.
Câu trả lời của Anthropic về việc làm thế nào để ngăn chặn việc này tiếp diễn: “Chính khả năng cho phép Claude được sử dụng trong các cuộc tấn công này cũng khiến nó trở nên quan trọng đối với phòng thủ mạng. Khi các cuộc tấn công mạng tinh vi chắc chắn xảy ra, mục tiêu của chúng tôi là để Claude - trong đó chúng tôi đã xây dựng các biện pháp bảo vệ mạnh mẽ - hỗ trợ các chuyên gia an ninh mạng phát hiện, phá vỡ và chuẩn bị cho các phiên bản tấn công trong tương lai.”
 Tóm tắt nhanh về cuộc tấn công của GTG-1002
Tóm tắt nhanh về cuộc tấn công của GTG-1002
AI (Claude Code) được dùng để:
- Tự động scan hệ thống mục tiêu
- Tự viết và test exploit code
- Tự dò credentials
- Tự đánh giá giá trị dữ liệu
- Tự exfiltrate
- Tự viết tài liệu tấn công đầy đủ
Dựa trên 3 yếu tố:
1. Code intelligence: tự viết payload tùy chỉnh
2. Agentic planning: chạy loop, ra quyết định, tự động nối tiếp nhiệm vụ
3. MCP (Model Context Protocol): truy cập công cụ thật như nmap, hydra, wireshark module, password cracker…
Tốc độ?
– Hàng ngàn requests mỗi giây. Con người không thể bắt kịp. Vậy Front-End dev phải chuẩn bị điều gì trong kỷ nguyên AI hacking?
Đây là lúc FE phải “lột xác”. Không còn chỉ viết UI, mà phải hiểu web security, attack surfaces, zero-trust architecture ngay từ tầng front-end. Dưới đây là 7 mảng bắt buộc mà một FE dev phải nắm khi AI agents bắt đầu tấn công ở quy mô lớn.
1. Token Security phải là kỹ năng bắt buộc
AI agents có thể:
• Dò token bị embed trong JS bundles
• Extract token từ localStorage
• Replay API calls
• Bypass client-side validation
Điều bạn cần làm ngay:
- Không lưu access token / refresh token trong localStorage
- Chuyển hết sang HTTP-only secure cookies
- Rotation mỗi 5–10 phút
- Implement “idle token invalidation”
- “Record & replay attack detection” ở BE (user không thể gửi 500 requests/s)
2. Giảm tối thiểu Attack Surface từ Front-End
AI agents có khả năng scan endpoints và UI flows nhanh hơn con người hàng ngàn lần.
FE phải hạn chế:
✘ Các hidden API endpoints
✘ API để debug còn sót
✘ Feature flags lộ ở client
✘ “Admin UI” được giấu bằng điều kiện ở FE (điều này AI bypass 100%)
✔️ Build-time feature gating
✔️ Strict CSP header
✔️ Tắt source map trong production
✔️ Obfuscation JS level 1–2 (đủ để chống scanning tự động, không cần quá mạnh)
3. Toàn bộ input từ user phải được xem như hostile
AI có thể generate hàng triệu payload khác nhau để tìm ra bug:
- XSS
- Template injection
- DOM clobbering
- CSP bypass
- URL-based manipulation
FE cần:
- Escape mọi thứ render bằng innerHTML
- Không bao giờ trust URL params
- Use DOMPurify khi render rich content
- Dùng sandboxed iframes cho bất kỳ nội dung embed
4. Anti-Bot không còn đủ: Cần Anti-Agent
AI agents mạnh đến mức:
- Bypass CAPTCHA (text/image/video)
- Bypass fingerprinting
- Bypass simple behavior detection
Bạn cần cập nhật sang Agent Detection:
- Random DOM mutation traps
- Random event sequencing
- Invisible interaction challenges
- Detect “non-human event timing patterns”
- Proof-of-work (Ethereum-style micro puzzles)
Nói cách khác: Nếu trước đây ta chống bot, thì giờ phải chống tác nhân AI có năng lực hành động & suy luận.
5. FE phải học về Supply Chain Security
GTG-1002 đã dùng MCP để điều khiển công cụ thật → nghĩa là AI có thể tấn công supply chain cực nhanh.
Một FE hiện đại phải hiểu:
✔️ Dependency reviews
✔️ NPM package integrity
✔️ Lockfile audit
✔️ Subresource Integrity (SRI)
✔️ Self-hosting critical scripts
✔️ Không dùng npm package không maintainer từ lâu
Frontend giờ là cánh cửa phổ biến nhất để tấn công chuỗi cung ứng.
6. FE phải push BE và Security Team thực hiện Zero-Trust
FE dev không thể nghĩ “BE sẽ lo vụ này”.
Với AI-capable attackers, mọi sai lầm nhỏ phía FE đều trở thành vector để AI exploit.
Bạn cần phối hợp BE để:
- Bảo vệ APIs theo nguyên tắc Zero-Trust
- Không attach permission logic ở FE
- Rate limits theo user/device/IP/fingerprint
- Monitoring real-time anomaly traffic
- WAF signatures đặc biệt cho agentic AI attacks
7. FE nên bắt đầu học cách dùng “AI để phòng thủ”
Anthropic nói rõ:
“Chính khả năng cho phép Claude bị khai thác trong cuộc tấn công cũng là lý do nó trở thành công cụ mạnh nhất để phòng thủ.”
Nghĩa là:
🔥 Bạn dùng AI để giám sát chính AI đang tấn công bạn.
FE nên:
- Dùng AI để scan UI attack vectors
- Dùng AI để generate test payload
- Dùng AI để fuzz client-side logic
- Tự động hóa pentest các flows quan trọng
- Dùng AI Monitor (như Anthropic Guardian) theo dõi hành vi bất thường
Đây gọi là counter-AI — bảo mật bằng tác nhân AI chống lại tác nhân AI.
Kết luận: Kỷ nguyên “FE chỉ làm UI” đã kết thúc
GTG-1002 đánh dấu cột mốc:
- AI đã trở thành một hacker tự chủ
- FE đã trở thành một lớp phòng thủ tuyến đầu
- Tốc độ tấn công > tốc độ con người phản ứng
Front-end dev hiện đại phải chuyển mindset: UI Developer → Front-End Security Engineer
Bạn không cần trở thành hacker, nhưng bạn bắt buộc phải hiểu:
- Token flow
- CSP
- Origin policy
- Client isolation
- Supply chain
- AI agent detection
- Zero-trust on the client
Nếu không, bạn sẽ là điểm yếu nhất trong hệ thống — và AI agents sẽ tận dụng điều đó trong miliseconds.
