
Sự phát triển của kiến trúc Transformer đã trở thành nền tảng cho các mô hình ngôn ngữ lớn. Tuy nhiên, sự bùng nổ về kích thước mô hình đã dẫn tới việc hạn chế về phần cứng cũng như thời gian để huấn luyện phân tán LLM. Bài viết sau đây sẽ giải thích làm như nào để có thể chạy các mô hình này với những tài nguyên hạn chế, tiết kiệm chi phí khi huấn luyện phân tán LLM.
I. Bộ nhớ cần thiết để huấn luyện phân tán LLM là gì?
Trước khi huấn luyện 1 model ta cần tính toán xem kích thước của model và tài nguyên của ta có xem nó có phù hợp để chạy hay không. Vậy thì làm thế nào để tính toán được con số đó? Trong bài viết này ta sẽ mặc định sử dụng VRAM (RAM GPU).
1. Tham số model
Để có thể huấn luyện 1 model điều đầu tiên ta load tham số của model lên VRAM. Các model hiện nay mặc định sử dụng dạng fp32 tức sử dụng 32 bit (4 bytes) để biểu diễn mỗi 1 tham số. Tuy nhiên, hiện nay khi finetune ta chủ yếu sử dụng dạng fp16 (2 bytes) hoặc bf16 (2 bytes) để chạy cho tiết kiệm bộ nhớ mà vẫn giữ được độ chính xác gần như tương tự. Như vậy với một model LLM 8B tham số ta sẽ cần đến khoảng 16GB VRAM chỉ để load model lên.
2. Optimizer state
Optimizer mà thông dụng nhất được sử dụng hiện nay là Adam và các biến thể của nó. Với AdamW ta sẽ cần 12 bytes/ tham số. Bao gồm 4 byte cho việc sao chép mỗi tham số, 4 bytes/ tham số cho momentum, 4 bytes/ tham số cho variance. Như vậy với model LLM 8B ta cần 96GB cho lưu trạng thái optimizer. Ngoài ra, nếu muốn sử dụng tiết kiệm bộ nhớ hơn cho optimizer ta có thể sử dụng các biến thể 8 bit chỉ cần 6 bytes/ tham số của Adam hoặc SGD cần 8 bytes/ tham số. Tuy nhiên, điều này sẽ làm mô hình hội tụ chậm hoặc không hội tụ được.
3. Gradients
Gradient thì sẽ lưu trữ ở dạng fp32 hoặc fp16 tùy theo kiểu dữ liệu của model. Do đó, ta sẽ cần khoảng 2 bytes/ tham số và khoảng 16GB VRAM cho 8B tham số.
4. Activation và batch size
Hiện nay, các GPU đa phần bị nút thắt cổ chai bởi bộ nhớ chứ không phải tốc độ tính toán trong huấn luyện phân tán LLM. Do đó, recomputation/ checkpointing thường được sử dụng để đổi chi phí bộ nhớ lấy chi phí tính toán. Việc recomputation/ checkpointing activation hoạt động bằng cách tính toán lại các activation của một số lớp nhất định theo vì lưu trữ chúng trong GPU.
Phương trình dùng để tính bộ nhớ cần thiết để lưu trữ activation :
2sbLh < memory < sbhL (34 + 5as/h)
Với :
s là sequence length
b là batch size
h là hidden dim mỗi layer
L là số layer trong model
a là số head attention
Ví dụ với model LLaMA3.1 8B có sequence length = 4096, batch size = 1, hidden dim = 5325, layers = 32, head = 32, số attention là 32 thì số memory cần thiết là :
41,6GB < memory < 126GB
5. Nhận xét
Ta thấy một con số quá lớn chỉ để huấn luyện được model 8B tham số khi cần ít nhất 169GB RAM để huấn luyện phân tán LLM full fine tune. Và chúng ta nên nhớ các GPU to nhất cũng chỉ có 80GB VRAM như H100 hay A100. Do đó, việc huấn luyện trên 1 GPU duy nhất như bình thường chúng ta vẫn làm là không khả thi. Vậy có cách nào để huấn luyện được 1 model có kích thước lớn này hay không? Và có cách nào để giảm bộ nhớ này xuống? Hay làm thế nào để huấn luyện được nhanh hơn?
II. Huấn luyện phân tán LLM
1. Tổng quan về huấn luyện phân tán LLM
Huấn luyện phân tán giúp huấn luyện các model trên một cụm máy có GPU bằng cách phân phối lượng công việc huấn luyện trên các máy đó và đảm bảo rằng model có khả năng chịu lỗi và mở rộng. Mục tiêu chính của huấn luyện phân tán là giúp tăng tốc quá trình huấn luyện và có thể giúp huấn luyện các model lớn trên một máy duy nhất nếu không đủ tài nguyên tính toán.
Có 2 cách tiếp cận huấn luyện phân tán đó là Data Parallelism và Model Parallelism :
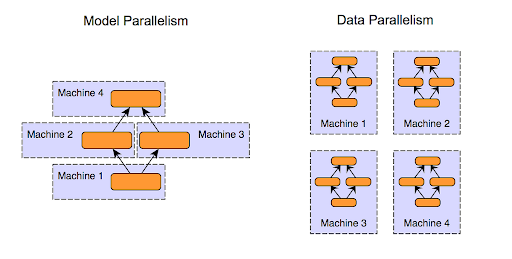
Data Parallelism :
Dữ liệu được chia thành các batch nhỏ và phân phối trên các máy tính khác nhau, mỗi máy được huấn luyện trên các batch dữ liệu riêng của nó.
Model Parallelism :
Model được chia thành các phần nhỏ hơn trên các máy khác nhau và mỗi máy huấn luyện một phần riêng của model bằng cách sử dụng cùng một batch dữ liệu huấn luyện. Phương pháp này hoạt động hiệu quả nhất khi các phần kiến trúc của model có thể được tính toán độc lập song song với nhau.
Trong phần này tôi sẽ giới thiệu về FSDP giúp cho việc training nhanh hơn và tiết kiệm bộ nhớ hơn. Đây là một phương pháp data parallelism phân mảnh các parameters, gradient và optimizer của model trên GPU tương tự với phương pháp Zero được đề xuất bởi deepspeed. FSDP giúp giảm mức sử dụng bộ nhớ vì sử dụng một mô hình được sao chép trên GPU. Điều này giúp cải thiện hiệu quả mức sử dụng bộ nhớ GPU cho phép huấn luyện các model lớn hơn trên.
2. Cách thức hoạt động của FSDP
2.1 FSDP Unit
Ví dụ bên dưới ta có 2 GPU sử dụng cho huấn luyện model bên dưới có 6 lớp. Ta chia ra làm 3 phân đoạn [layer 0, layer 3], [layer 1, layer 2], [layer 4, layer 5]. Mỗi phân đoạn được gọi là unit FSDP có các tham số được phân mảnh trên 2 GPU.
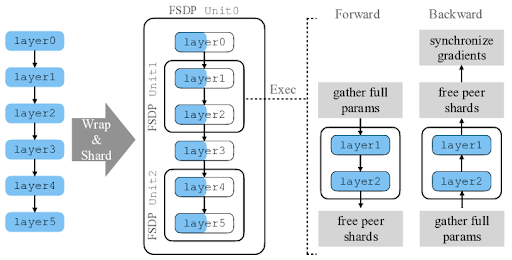
2.2 Chiến lược phân mảnh
FSDP cung cấp 2 chiến lược phân mảnh là : Phân mảnh hoàn toàn (Fully Sharding) và phân mảnh hỗn hợp (Hybrid Sharding). Fully Sharding sẽ tối ưu cho cụm GPU nhỏ kết nối với băng thông cao như NVLink có thể xử lý các giao tiếp lớn cần thiết cho các hoạt động All-Gather hoặc Reduce Scatter trong forward và backward. Còn Hybrid Sharding thiết kế cho cụm GPU lớn hơn kết hợp giữa NVLink tốc độ cao và PCIe băng thông chậm hơn.Với Fully Sharding, FSDP nhóm tất cả các tham số trong 1 unit FSDP sau đó làm bằng nó gọi là FlatParrameter. Sau đó, FlatParameter chia thành các phần bằng nhau gán cho các GPU khác nhau.
Với Hybrid Sharding, liên quan đến việc các phân mảnh nhỏ hơn tổng số GPU. Ví dụ ta có 16GPU và có 8 phân mảnh thì các GPU sẽ được chia làm 8 nhóm, mỗi nhóm 2 GPU hoạt động giao tiếp tương tự với Fully Sharding.
2.3 Quá trình forward
Trước khi bắt đầu forward trên các unit, mỗi GPU thu thập các tham số chưa phân mảnh cần thiết từ GPU khác thông qua All-Gather collective communication. Các tham số này cho phép xử lý cục bộ các layer trong mỗi GPU, với mỗi GPU xử lý batch riêng của mình song song tương tự với Data Parallelism. Sau khi xử lý từng unit FSDP, FSDP giải phóng các phân mảnh được thu thập tạm thời để giảm thiểu việc sử dụng bộ nhớ. Do đó, trong quá trình forward, FSDP chỉ thực hiện lan truyền trên 1 unit tại 1 thời điểm trong khi vẫn giữ các unit khác được phân mảnh, giảm đáng kể memory footprint nhưng đánh đổi lại là sự giao tiếp giữa các GPU.
2.4 Quá trình backward
Tương tự với forward, FSDP thu thập các tham số của unit trước khi tính toán và giải phóng chúng. Khi các phép tính gradient hoàn tất, nó kích hoạt Reduce-Scatter collective communication để phân mảnh các gradient đã reduce trên các GPU. Cuối cùng, mỗi GPU chỉ giữ lại một phân mảnh các tham số cùng với các gradient và optimizer state tương ứng, giảm dung lượng bộ nhớ cần thiết cho GPU trong quá trình huấn luyện model.
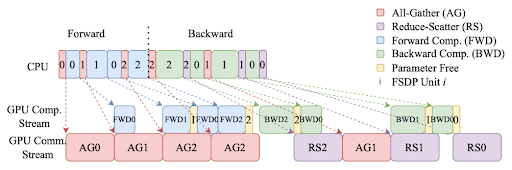
FSDP sử dụng nhiều tối ưu khác nhau để huấn luyện hiệu quả. Trong 1 step huấn luyện, CPU khởi chạy các luồng tính toán và giao tiếp và overlap chúng càng nhiều càng tốt. Bên dưới hình ảnh mô tả quá trình overlap giữa tính toán và giao tiếp.
2.5 Zero Redundancy Optimizer
FSDP được xây dựng dựa trên kỹ thuật được gọi là Zero Redundancy Optimizer:

Stage 1 : Chỉ phân mảnh các optimizer state
Stage 2 : Phân mảnh cả optimizer và gradient
Stage 3 : Phân mảnh cả weight, gradient, optimizer.
III. Kết luận
FSDP là kỹ thuật huấn luyện phân tán LLM được phát triển dựa bởi Pytorch tương tự với kỹ thuật Zero đề xuất bởi deepspeed giúp cho huấn luyện hiệu quả hơn, giúp giảm bộ nhớ cần thiết để có thể huấn luyện các model có kích thước to.
Trong quá trình huấn luyện phân tán LLM, ta có thể sử dụng RAM CPU khi hạn chế phần cứng bằng cách sử dụng offload cpu để tiết kiệm bộ nhớ. FSDP sẽ hiệu quả khi huấn luyện các model có kích thước hàng tỷ tham số, có nhiều GPU và ta cần đánh đổi thời gian huấn luyện với phần cứng
Lưu ý: FSDP không nên sử dụng trong trường hợp model kích thước nhỏ chỉ hàng triệu tham số.
Xem thêm bài viết về Machine Learning.




