
Mixture of Expert (MoE) là một kỹ thuật kết hợp nhiều mô hình expert lại với nhau để cải thiện hiệu suất tổng thể. Trong đó, mỗi model expert được huấn luyện trên một tập dữ liệu sao cho mỗi expert sẽ chuyên về dữ liệu này. Sau đó, chúng ta tạo đầu ra của model bằng cách kết hợp các chuyên gia này, thông thường sẽ sử dụng kết hợp các trọng số để tạo ra 1 đầu ra duy nhất cuối cùng. Kỹ thuật này đã xuất hiện từ năm 1991 nhưng hiện nay nó trở nên nổi tiếng hơn khi Mistral phát hành model Mistral-8x7B.
1. Kiến trúc MoE
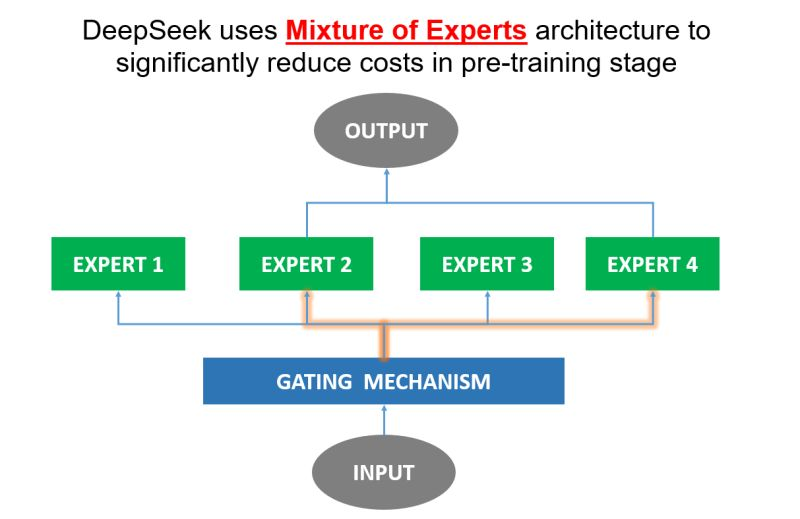
Nền tảng cho kiến trúc MoE nằm ở các expert và cơ chế gating.
- Expert : Mỗi expert là một mạng neural riêng biệt được huấn luyện trên một loại dữ liệu đặc biệt dành cho expert đó để thực hiện tốt trên 1 nhiệm vụ hoặc tập dữ liệu cụ thể. Sự chuyên môn hóa này giúp cho các expert xử lý các dữ liệu phức tạp hiệu quả hơn.
- Cơ chế gating : Cơ chế này đóng vai trò quan trọng trong MoE bằng cách đưa ra lựa chọn expert nào sẽ được sử dụng để phù hợp cho mỗi đầu vào. Nó hoạt động như một router đảm bảo chỉ có những expert phù hợp nhất được lựa chọn để đóng góp vào đầu ra cuối cùng.
2. Cách huấn luyện MoE
Để huấn luyện MoE ta sẽ cần tối ưu hóa đồng thời weight của các expert và cơ chế gating. Mục tiêu là huấn luyện ra được các expert cho ra kết quả tốt nhất với các input đầu vào và router luôn đưa input đến với expert phù hợp nhất.
- Phương pháp truyền thống hay được sử dụng là EM để tối đa hóa kỳ vọng. Đầu tiên, router sẽ gán xác suất cho twnmfg expert dựa trên dự đoán hiện tại. Sau đó, các weight của expert và router sẽ được cập nhật để tối đa hóa hiệu suất tổng thể của mô hình.
- Hiện nay, phương pháp học tăng cường đang được sử dụng để thay thế cho EM giúp giảm độ phức tạp tính toán liên quan và hợp lý hóa quy trình huấn luyện và đạt được các kết quả khả quan tiêu biểu là Deepseek.
3. Các biến thể của MoE
Các biến thể MoE có thể được phân loại dựa trên phương pháp huấn luyện hoặc sự thay đổi kiến trúc của nó.
- Sparse MoE : Sử dụng một tập con các expert cho 1 input cụ thể. Ví dụ với Mistral 8x7B sẽ sử dụng 2 trong số 8 expert cho mỗi token.
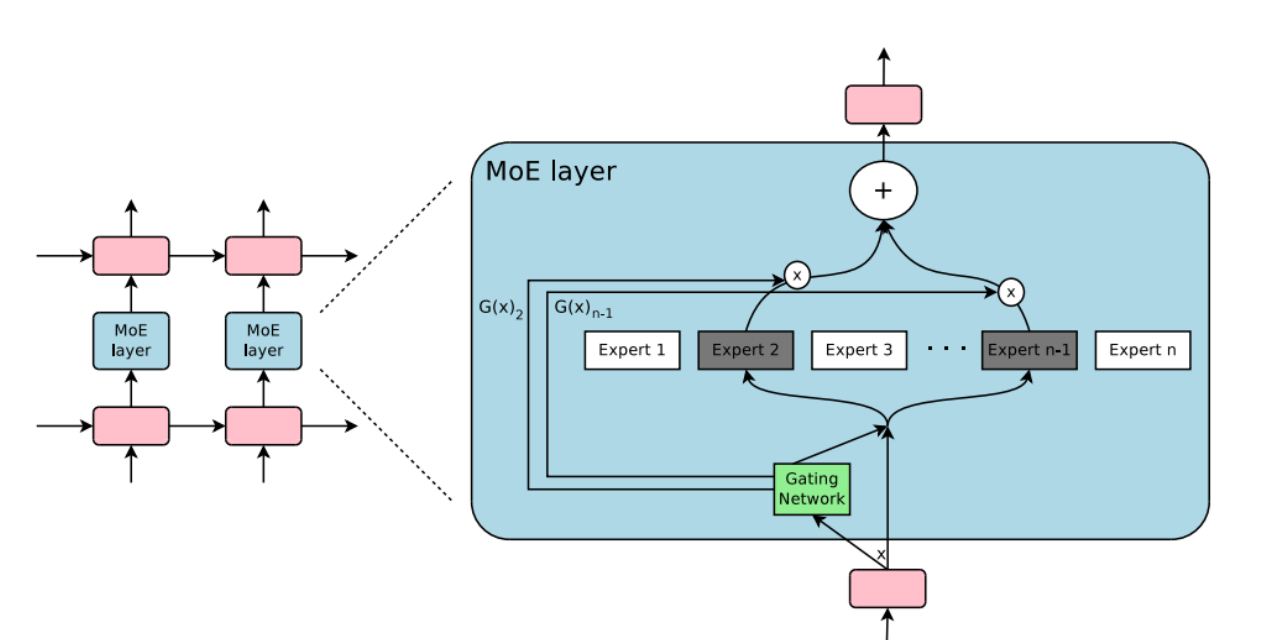
- Hard MoE : Với 1 đầu vào ta sẽ chọn duy nhất 1 expert cụ thể để dự đoán.
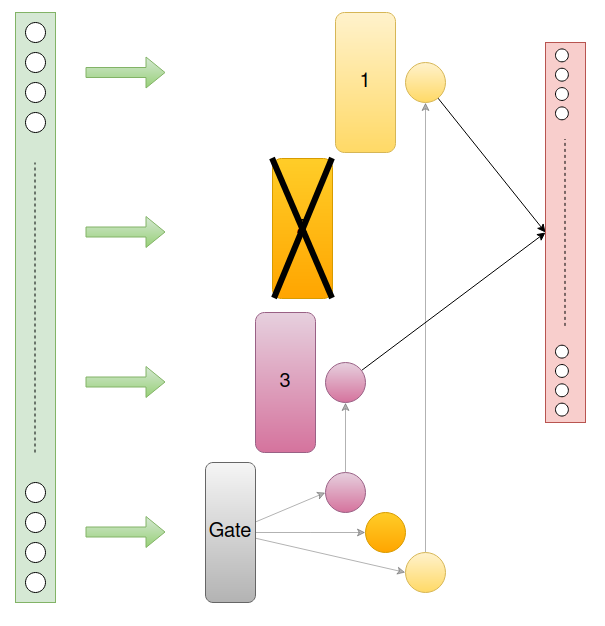
- Soft MoE : Ta sử dụng xác suất để gán cho các expert với mỗi input. Sau đó, các xác suất này được dùng cho dự đoán đầu ra cuối cùng. Ví dụ ta có 4 expert và 1 input đầu vào. Router sẽ gán xác suất cho 4 expert là [0.1, 0.2, 0.3, 0.4] tương ứng với việc góp vào xác suất tổng thể của các expert cho đầu ra cuối cùng.
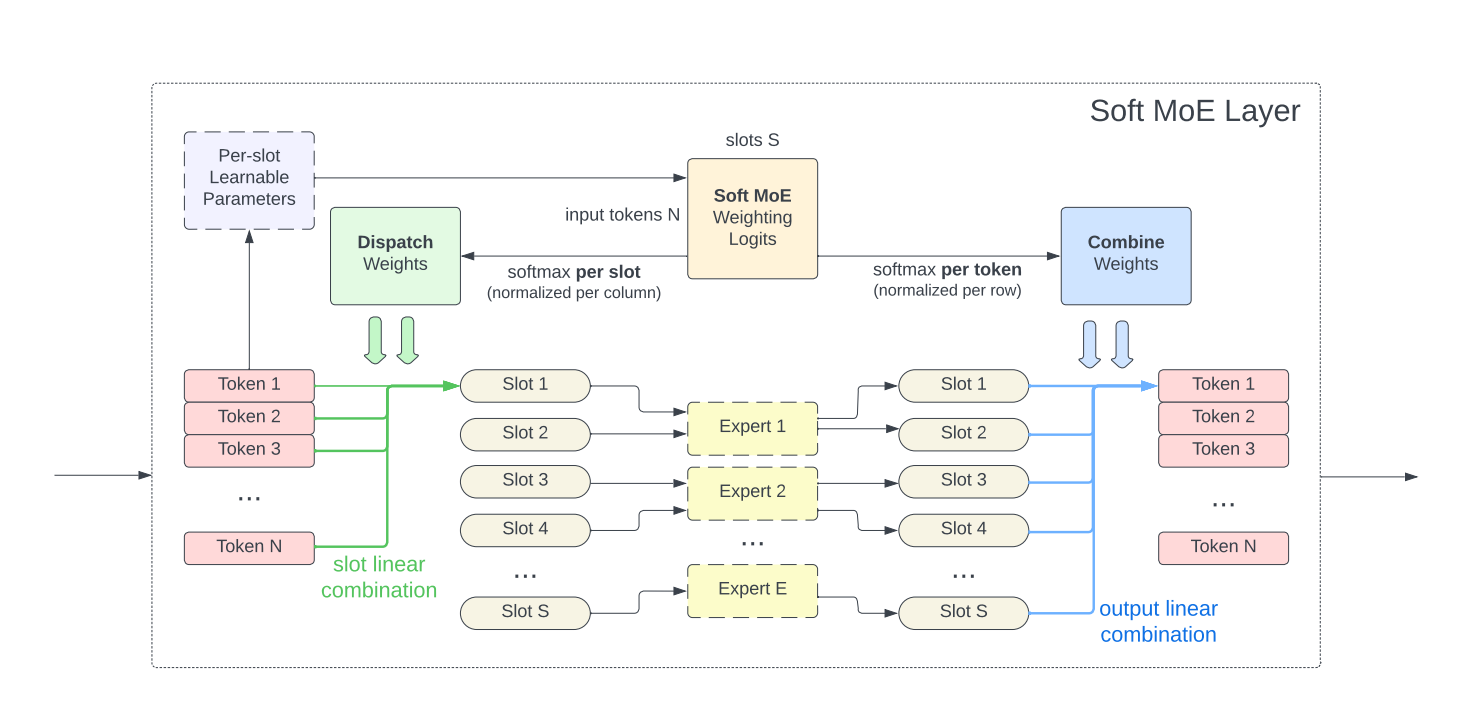
- Hierarchical MoE: Phân các chuyên gia thành các cấp khác nhau để xử lý cho input. Ví dụ cấp đầu tiên cho expert trả lời các nhiệm vụ chung và expert chuyên về code. Với expert chuyên về code sẽ phân cấp ra các expert chuyên code về ngôn ngữ lập trình khác nhau.
4. Ưu điểm và hạn chế của MoE
- Ưu điểm:
- Giảm tải số lượng tính toán : Không giống với các mô hình Dense, các model MoE giảm tải số lượng cần tính toán trong quá trình inference hạn chế tốc độ tính toán của các GPU. Tuy nhiên, yêu cầu về lượng RAM vẫn không đổi khi vẫn phải load hết các expert lên GPU
- Tính linh hoạt và mở rộng: MoE có thể kết hợp nhiều loại mô hình expert và cơ chế gating khác nhau cùng với đó là có thể mở rộng để xử lý các tập dữ liệu lớn và nhiệm vụ phức tạp
- Nhược điểm:
- Độ phức tạp trong quá trình huấn luyện : Huấn luyện các model MoE phức tạp và khó khăn khi phải tối ưu hóa đồng thời cả expert và gating.
- Nhu cầu sử dụng bộ nhớ cao : Mặc dù các model MoE chỉ sử dụng một phần tham số của các expert trong quá trình inference nhưng vẫn cần phải tải các expert này lên thiết bị dẫn đến yêu cầu sử dụng bộ nhớ cao.
- Cân bằng tải : Khi các expert được phân bổ trên nhiều thiết bị làm tắc nghẽn tính toán
5. Một số model sử dụng MoE
5.1 Mixtral-8x7B

- Mixtral-8x7B sử dụng kiến trúc decode thông thường nhưng thay thế lớp Feed Forward Network bằng gating và theo sau là 8 expert. Khối mã này được lặp lại 32 lần để tạo thành model Mixtral-8x7B.
- Trong Mixtral-8x7B, với mỗi token gating sẽ định tuyến model đến 2 expert trong số 8 expert. Sau đó, đầu ra được cộng lại theo xác suất của gating đánh cho 2 expert này. Cuối cùng, được đi qua lớp softmax và logit để ra output cuối cùng.
- Trong quá trình huấn luyện, các token trong được chuyển tới các expert khá đều không có sự riêng biệt.
- Mixtral-8x7B có tổng tham số là 46,7B tham số vì ngoài các expert dùng riêng ra thì các lớp khác vẫn được sử dụng chung. Trong quá trình inference, model chỉ sử dụng 13B tham số nên suy luận nhanh hơn so với các model Dense khác có kích thước tham số tương tự.
5.2 DeepSeek
DeepSeek MoE đã có một số cải tiến trong cách hoạt động bao gồm:
- Phân chia các expert thành các nhóm mN và kích hoạt $mK$ từ các nhóm đó: Cụ thể, thu nhỏ kích thước của hidden dim của Feed Forward Network bằng $\frac{1}{m}$ kích thước ban đầu của nó. Mỗi FFN của expert sẽ được chia thành m expert nhỏ hơn tạo ra tổng số $mN$ expert. Vì số expert chia nhỏ hơn nên số lượng expert được kích hoạt chạy tăng lên theo hệ số m thành $mK$ expert được kích hoạt.
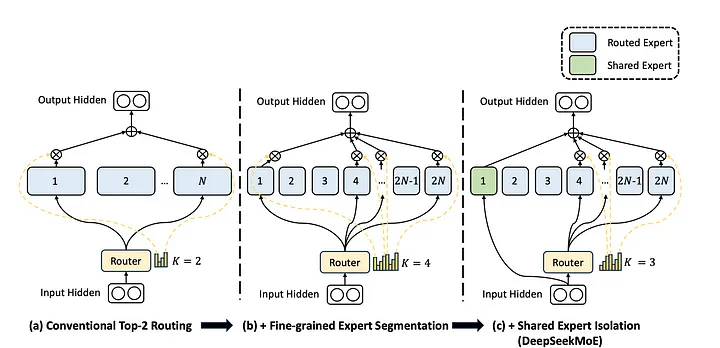
- Tách biệt các expert thành 1 chuyên gia chung. Trong chiến lược truyền thống, các expert có thể cùng học một kiến thức chung gây dư thừa tham số. Các expert được chia sẻ sử dụng để nắm bắt và tích hợp kiến thức chung từ các bối cảnh khác nhau, giúp giảm bớt sự dư thừa khi các expert có được kiến thức chung, giúp cho các expert khác tập trung vào học các kiến thức đặc biệt khác làm hiệu quả tham số.
Ngoài ra, DeepSeek còn tối ưu hóa cho cho routed experts tránh tắc nghẽn tính toán dẫn đến mất cân bằng tải và vấn đề model chỉ chọn một vài expert khiến các expert khác không được huấn luyện đầy đủ ảnh hưởng đến hiệu suất chung trong việc thực hiện chuyên môn hóa model.
6. Kết luận
MoE là một kỹ thuật đầy hứa hẹn và đang đạt được những thành công nhất định trong việc cải thiện chất lượng mô hình LLM. MoE cho phép huấn luyện và triển khai hiệu quả giúp vượt qua các kiến trúc Dense truyền thống.


