
Giới thiệu
Việc triển khai các mô hình ngôn ngữ lớn (LLM) đặt ra nhiều thách thức về mặt kỹ thuật, đặc biệt trong bối cảnh độ phức tạp của các mô hình ngày càng gia tăng. Những mô hình này thường yêu cầu phần cứng có hiệu năng cao, với dung lượng bộ nhớ lớn để có thể xử lý khối lượng dữ liệu và tham số khổng lồ. Điều này không chỉ ảnh hưởng đến chi phí hạ tầng mà còn đòi hỏi sự tối ưu hóa kỹ lưỡng trong quá trình phục vụ mô hình. Phần dưới đây trình bày một kiến trúc hệ thống serving LLM, được thiết kế để đáp ứng các yêu cầu về hiệu năng và khả năng mở rộng trong môi trường thực tế.
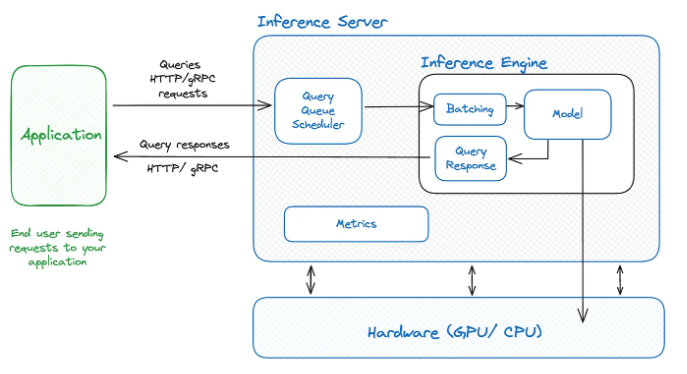
Các end user sẽ gửi các truy vấn đến ứng dụng và các truy vấn này chuyển đến một inference server và sau đó chúng được đưa vào queue và quản lý bởi bộ lập lịch schedule. Bộ lập lịch này sẽ xác định xem thời điểm thích hợp để đưa vào xử lý từng yêu cầu dựa trên các tài nguyên phần cứng có sẵn. Trong inference server thì inference engine phụ trách việc gom các request lại thành batching để tối ưu hóa hiệu suất trước khi chúng được xử lý và phản hồi lại cho người dùng.
1. Prefill và Decoding
Trong quá trình suy luận (inference) của các mô hình ngôn ngữ lớn (LLM), việc sinh đầu ra không diễn ra một cách đơn giản hay liền mạch, mà được chia thành hai giai đoạn chính là prefill và decode. Mỗi giai đoạn đóng một vai trò quan trọng và có đặc điểm kỹ thuật riêng biệt, ảnh hưởng trực tiếp đến hiệu suất và tốc độ xử lý của toàn bộ hệ thống. Việc hiểu rõ bản chất của hai giai đoạn này là điều cần thiết để tối ưu hóa quá trình triển khai và phục vụ mô hình
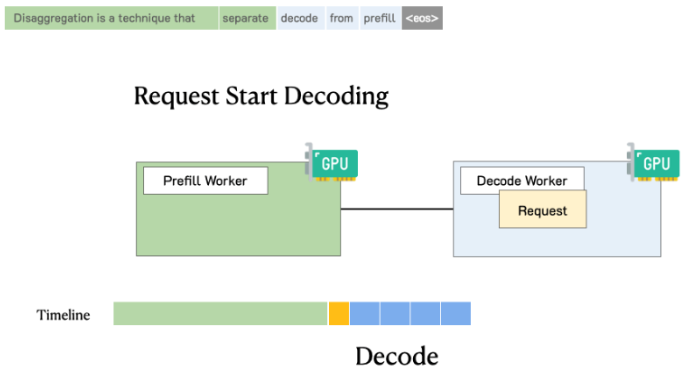
1.1 Prefill
- Trong quá trình này, model xử lý văn bản đầu vào bằng cách chuyển các input đầu vào thành các token. Nó tính toán các biểu diễn trung gian cần thiết như KV cache, lưu trữ thông tin về token đầu vào.
- Mục tiêu chính của quá trình prefill để model có thể generate đầu ra. Nó yêu cầu nhiều tính toán và có thể song song hóa cao giúp xử lý hiệu quả dữ liệu đầu vào cùng lúc. Giai đoạn này thường tốn nhiều tính toán và tận dụng tối đa sức mạnh của GPU.
1.2 Decoding
- Trong quá trình decode model tạo ra các token đầu ra một cách tuần tự. Mỗi token mới được dự đoán dựa trên các token trước đó được tạo ra và thông tin được lưu trữ trong KV Cache từ giai đoạn prefill.
- Mục tiêu quá trình này là tạo ra các token mạch lạc và có liên quan đến contex cho prompt. Việc tạo ra token tiếp theo sẽ phụ thuộc vào các token trước đó. Giai đoạn này chậm hơn so với prefill vì thực hiện tuần tự dẫn đến không sử dụng hết khả năng song song hóa của GPU. Giai đoạn này sẽ dừng cho đến khi đạt max token hoặc sinh đến stop token.
2. Batching
GPU là kiến trúc song song với tốc độ tính toán mạnh. Mặc dù có khả năng tính toán mạnh nhưng LLM vẫn gặp khó khăn khi phần lớn bị nghẽn vì băng thông bộ nhớ của GPU bị giới hạn và phần lớn chỉ được dùng để tải các tham số. Và việc xử lý theo batch là một cách để cải thiện tình hình này. Thay vì tải các tham số mới mỗi lần có một chuỗi input đầu vào ta có thể tải các tham số mô hình một lần rồi dùng chúng để xử lý nhiều chuỗi đầu vào. Điều này sử dụng hiệu quả hơn băng thông bộ nhớ dẫn đến việc sử dụng tính toán cao hơn, thông lượng cao hơn và rẻ hơn.
2.1 Navie Batching
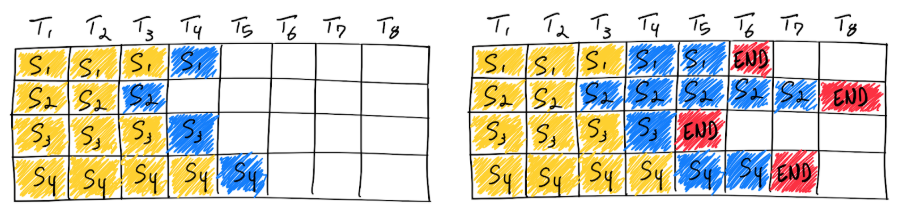
- Cách tiếp cận truyền thống này kích thước của batch không đổi và dung lượng bộ nhớ sử dụng cho đến khi quá trình inference hoàn tất.
- Không giống các model deep learning truyền thống, việc xử lý batch cho LLM khó khăn do bản chất regression trong quá trình inference của chúng. Theo ý nghĩ thông thường thì ta có thể yêu cầu nó hoàn thành sớm một số yêu cầu trong một batch nhưng rất khó để có thể giải phóng tài nguyên của chúng và thêm các yêu cầu khác mới vào batch ở các trạng thái hoàn thành khác nhau. Điều này có nghĩa là GPU sẽ không được sử dụng hết công suất vì độ dài của các chuỗi trong batch là khác nhau. Trong hình trên được minh họa với các ô màu trắng của các request sau khi kết thúc quá trình generate ở các batch vẫn không được giải phóng.
- Ví dụ với việc sử dụng batch để hỏi các câu đơn giản có cùng kích thước đầu vào là 128 token và đầu ra đều là 16 token thì naive batching sẽ hiệu quả. Tuy nhiên, các dịch vụ chatbot như GPT có độ dài input đầu vào là không cố định và đầu ra cũng không cố định số lượng token. Với việc sử dụng naive batching dẫn đến tình trạng sử dụng GPU không hiệu quả làm cho chi phí sử dụng vô cùng lớn.
2.2 Continue Batching
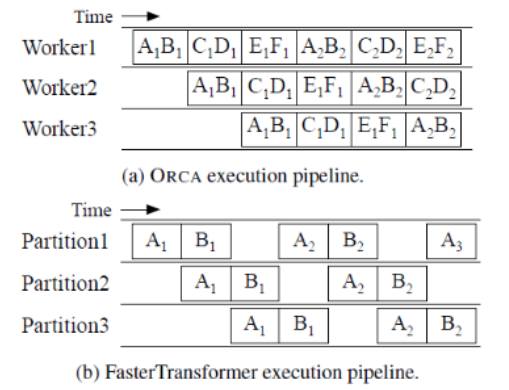
- Với vấn đề lớn của naive batching như vậy thì ORCA đã đưa ra một cách tiếp cận mới để giải quyết vấn đề này. Thay vì chờ cho đến khi mọi chuỗi trong 1 batch hoàn tất việc sinh token, ORCA triển khai lập lịch với cấp độ lặp lại trong đó kích thước batch được xác định theo từng lần lặp lại. Kết quả là sau khi một chuỗi trong 1 batch hoàn tất, một chuỗi mới có thể được chèn vào vị trí của nó làm cho GPU luôn ở mức sử dụng cao.
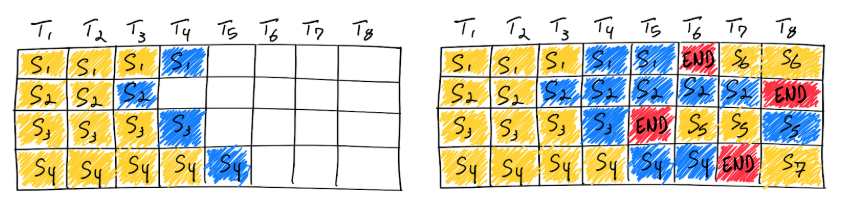
Iteration-level scheduling : ORCA đưa ra các endpoint để xử lý các yêu cầu inference. Vai trò của trình lập lịch này là chọn các yêu cầu từ nhóm, lập lịch cho các tool thực thi để chạy 1 lần lặp mô hình trên các yêu cầu đó, nhận token đầu ra từ tool và cập nhật nhóm cho phù hợp. Tool thực hiện các hoạt động tensor có các khả năng song song hóa trên nhiều GPU và máy. Scheduler quyết định động các yêu cầu nào sẽ được thực thi trong 1 lần lặp cho phép linh hoạt trong việc xử lý các yêu cầu gửi đến. Khi request hoàn thành sẽ sẽ bị xóa khỏi nhóm và respond sẽ gửi đến endpoint.
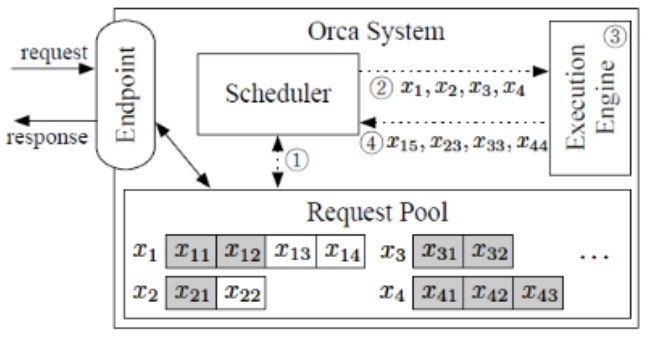
Selective batching : Giúp tăng cường tính linh hoạt trong việc thực thi split batch trong xử lý mô hình bằng cách áp dụng split batch có chọn lọc thay vì áp dụng chung cho tất cả các tensor. Các hoạt động như nhân ma trận attention và normalize, selective batching sẽ làm phẳng thành cấu trúc 2D duy nhất. Cách tiếp cận này dựa trên cơ sở từng token nên cho phép các token từ các request khác nhau được xử lý như thể chúng cùng 1 request. Tuy nhiên, với các hoạt động attention, yêu cầu các cặp KV duy nhất cho mỗi request, split batch được chia nhỏ và mỗi request xử lý riêng lẻ. Sau khi hoạt động attention hoàn tất các đầu ra được hợp nhất thành 1 tensor duy nhất cho các hoạt động tiếp theo.

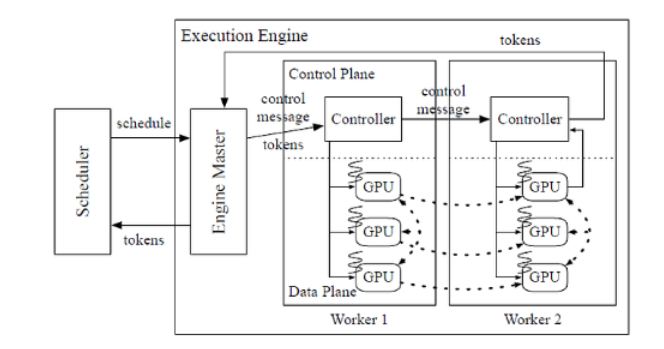
Distributed Architecture : ORCA kết hợp 2 kỹ thuật song song hóa mô hình cho các mô hình transformer là intra-layer và inter-layer parallelism. Với intra-layer parallelism chia các phép nhân ma trận và các tham số của chúng trên nhiều GPU. Mặt khác, inter-parallelism chia các lớp transformer trên nhiều GPU. Tool thực thi ORCA tạo điều kiện cho việc chạy phân tán bằng cách quy định mỗi worker chỉ cho một máy khác nhau chịu trách nhiệm quản lý một hoặc nhiều luồng CPU điều khiển GPU. Mỗi GPU điều khiển một phân vùng inter-layer của mô hình và số luồng được xác định theo mức độ song song trong lớp. Khi mà một lần lặp lại của model được lên lịch cho batch request, tool cung cấp server cho worker đầu tiên thông tin cần thiết. Sau đó, worker này chuyển message đến worker tiếp theo mà không cần chờ các task GPU nó hoàn tất. Worker cuối cùng đảm bảo rằng các task GPU của nó hoàn tất trước khi thu thập các token đầu ra và gửi chúng lại tool server. Phương pháp này cho phép thực thi phân tán hiệu quả trên nhiều máy và GPU.
Thuật toán lập lịch : Scheduler của ORCA được thiết kế để quản lý hiệu quả quá trình yêu cầu bằng cách chọn một số lượng yêu cầu giới hạn dựa trên thời gian chúng đến. Khi lập lịch request đầu tiên nó sẽ dành cho các khe cắm bộ nhớ để lưu KV cần thiết. Quá trình lập lịch bao gồm chọn 1 batch request từ group trong đó hàm select đảm bảo rằng các yêu cầu đã chọn được ưu tiên theo thời gian tới. Bộ lập lịch cũng kiểm tra có đủ bộ nhớ cho các yêu cầu mới hay không dựa trên số token tối đa được yêu cầu. Bộ lập lịch ORCA cũng tối ưu hóa việc thực thi của các worker bằng cách đưa các task vào nhiều batch. Thay vì chờ từng batch hoàn thành trước khi lên lịch cho batch tiếp theo thì bộ lập lịch đảm bảo rằng số lượng các batch chạy đồng thời bằng với số worker.
3. Paged Attention
- Các nghiên cứu chỉ ra rằng các hệ thống hiện tại đang lãng phí 60-80% bộ nhớ KV-Cache. Do đó cần phải có một phương pháp để cải thiện sự lãng phí bộ nhớ này giúp sử dụng ít GPU hơn để đạt cùng một đầu ra.
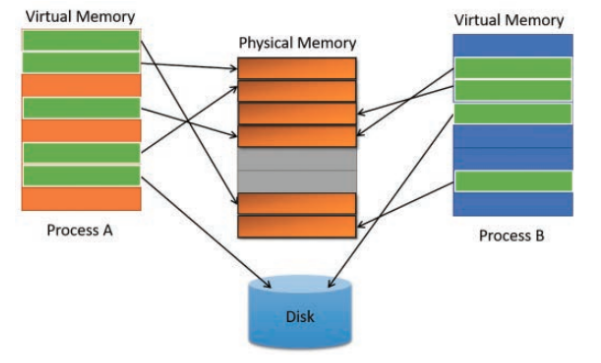
Paged Attention đã lấy cảm hứng từ phân trang bộ nhớ ảo của các hệ điều hành để quản lý và phân bổ các phần bộ nhớ của máy tính. Nó cho phép sử dụng bộ nhớ hiệu quả hơn và giảm lãng phí.
3.1 KV-Cache
Bộ đệm KV cache đóng vai trò then chốt trong việc xử lý và sinh văn bản bằng các phép tính ma trận sử dụng cơ chế self-attention xác định phần văn bản hiện tại có liên quan đến vector được sinh ra. Với mỗi token sinh ra ta sẽ cần thực hiện phép nhân ma trận các giá trị Q,K,V dẫn đến việc yêu cầu tính toán lớn.
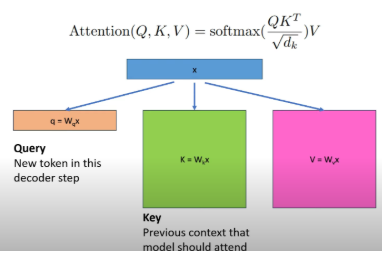
Do đó, thay vì tính toán lại các giá trị các cặp KV này cho mỗi lần sinh ra token mới, ta sẽ lưu trữ ma trận KV để có thể tái sử dụng trong các phép tính tiếp theo. Cache ban đầu trống và ta cần tính toán trước bộ nhớ để cấp phát cho toàn bộ chuỗi để bắt đầu sinh ra token mới. Tuy nhiên, việc triển khai KV cache truyền thống như này gây lãng phí lớn khi hầu hết không sử dụng đến.
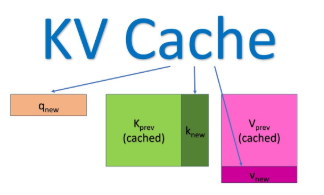
3.2 Tối ưu hóa KV cache bằng Paged Attention
- Các hệ thống lưu trữ cặp KV cache trong không gian bộ nhớ liên tục. Tuy nhiên, nó gây lãng phí lớn khi gây ra một số vấn đề:
- Phân mảnh trong: Các bộ nhớ được cấp phát tối đa ngay khi bắt đầu sinh ra token đầu tiên nhưng không bao giờ sử dụng hết vì hệ thống không biết model sẽ tạo ra bao nhiêu token.
- Reservation : Để đảm bảo quá trình sinh token không bị gián đoạn, hệ thống sẽ dành riêng toàn bộ nhớ nhớ trong suốt quá trình sinh token. Ngay cả khi chỉ một phần bộ nhớ dành riêng đó được sử dụng còn các phần còn lại đó vẫn còn nhưng không thể được các request khác truy cập sử dụng.
- Phân mảnh ngoài : Phân mảnh ngoài xảy ra khi các bộ nhớ có kích thước cố định không khớp với bộ nhớ mới yêu cầu dẫn đến khoảng trống không sử dụng giữa chúng mà không thể cấp phát cho các tiến trình khác.
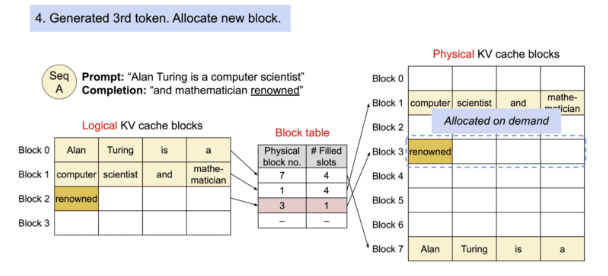
- Kết quả dẫn tới khoảng 60-80% bộ nhớ KV cache được cấp phát mà không được sử dụng. Do đó, Paged Attention áp dụng kỹ thuật phân trang bộ nhớ để quản lý KV cache hiệu quả hơn. Nó phân bổ các khối một cách động, cho phép hệ thống lưu trữ các khối liên tục trong các phần tùy ý của không gian bộ nhớ chung.
- Paged Attention loại bỏ phân mảnh ngoài nơi các khoảng trống giữa các khối bộ nhớ cố định không được sử dụng và giảm thiểu phân mảnh trong khi bộ nhớ được cấp phát vượt mức yêu cầu thực tế. Việc sử dụng Paged Attention đã giúp giảm lãng phí bộ nhớ KV Cache từ 60-80% xuống khoảng 4% bộ nhớ giúp cho inference với batch size lớn hơn.
- Ngoài ra, Paged attention còn một vài hữu ích khác như sampling/decoding song song. Phương pháp này giúp tạo ra nhiều token đầu ra cùng 1 lúc với cùng 1 prompt. Giúp cho có nhiều phản hồi và lựa chọn phản hồi tối ưu. Tạo ra các đầu ra với chiến lược decode hỗn hợp như top-p, top-k,..
4. Radix Attention
4.1 Vấn đề dư thừa trong khi xử lý prefix
- Trong quá trình serving mô hình ngôn ngữ lớn (LLM), sau mỗi lần inference, hệ thống thường giải phóng toàn bộ KV cache – bao gồm các biểu diễn trung gian được tính toán trong giai đoạn prefill. Điều này dẫn đến một hạn chế quan trọng: các request khác nhau dù có chung phần đầu vào (prefix) vẫn không thể tận dụng lại kết quả đã tính, gây ra các tính toán dư thừa và giảm hiệu suất xử lý.
- Thách thức này càng rõ rệt hơn trong các hệ thống cần xử lý các batch truy vấn với nội dung tương tự (ví dụ như chat, tìm kiếm theo ngữ cảnh). Để giải quyết, một hướng tiếp cận hiệu quả đã được đề xuất: sử dụng cấu trúc dữ liệu radix tree để lưu trữ và truy xuất KV cache dựa trên prefix.
4.2 Radix Attention
- Radix Attention là một kỹ thuật được phát triển nhằm tối ưu việc tái sử dụng KV cache giữa các truy vấn có phần đầu vào giống nhau. Phương pháp này sử dụng radix tree để tổ chức và quản lý KV cache một cách có hệ thống: mỗi node trong cây đại diện cho một chuỗi token, đi kèm với các vector KV cache tương ứng.
- Khi một truy vấn mới đến, hệ thống sẽ thực hiện tìm kiếm trong radix tree để xác định prefix dài nhất khớp với chuỗi token đầu vào. Nếu tìm thấy, KV cache tương ứng sẽ được tái sử dụng, giúp giảm thiểu tính toán trong giai đoạn prefill.
- Thay vì loại bỏ KV cache sau khi kết thúc một request, hệ thống sẽ lưu trữ chúng trong radix tree và ánh xạ chúng theo chuỗi token tương ứng. Đối với các phần không còn sử dụng, Radix Attention áp dụng chiến lược loại bỏ theo thuật toán LRU (Least Recently Used) để giải phóng bộ nhớ một cách thông minh và hiệu quả.
- Nhờ khả năng tái sử dụng KV cache theo prefix, Radix Attention đặc biệt phù hợp với các ứng dụng có lượng lớn truy vấn liên tiếp hoặc song song với nội dung tương đồng. Tuy nhiên, với những trường hợp truy vấn có ngữ cảnh đầu vào đa dạng, không chia sẻ prefix, hoặc yêu cầu cực kỳ thấp về độ trễ và quản lý bộ nhớ tối ưu, việc áp dụng phương pháp này cần được cân nhắc kỹ lưỡng.
5. Speculative Decoding
Với nhu cầu tạo các văn bản real time hoặc near real time ngày càng tăng từ các model trong khi kích thước các model ngày càng tăng theo cấp số nhân khi chứa trăm tỷ tham số. Dẫn đến việc phải có chiến lược inference hiệu quả để đáp ứng nhu cầu vừa nhanh vừa rẻ. Speculative đã sử dụng khéo léo 2 model cùng lúc với một model distillation kích thước bé dùng để generate token và 1 model đích để validate token sinh ra để thực hiện điều này.
5.1 Decoding truyền thống
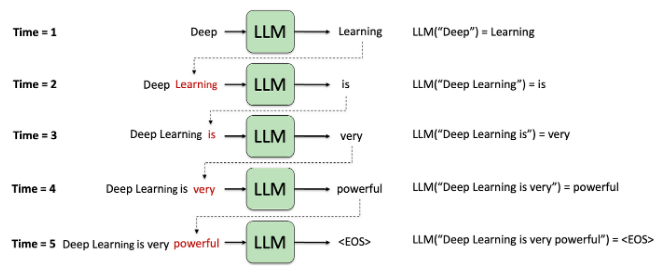
- Với decoding truyền thống, với đầu vào là context được sinh ra ở step trước hoặc prompt sẽ được model sử dụng để dự đoán phân phối xác suất. Sau đó, một token sẽ được lựa chọn dựa trên các phương pháp như sampling hoặc greedy search,… Và với trường hợp chúng ta cần sinh ra n token thì sẽ cần model chạy n lần forward dẫn đến chi phí mỗi lần sinh ra token tăng lên cao khi token đằng sau sẽ phụ thuộc vào các token đằng trước.
5.2 Speculative decoding
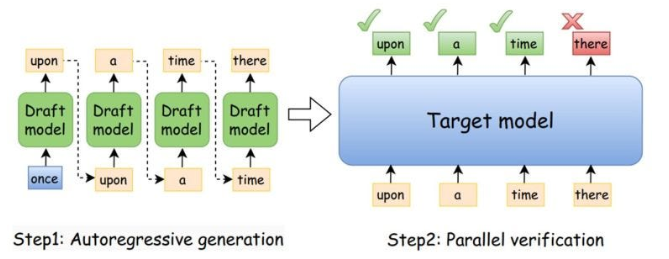
- Speculative decoding xuất hiện để giải quyết vấn đề này. Nó khéo léo kết hợp sử dụng model nhỏ hơn nhiều so với model target để sinh ra các token theo tuần tự một cách nhanh hơn nhiều so với model target. Sau đó các token sinh ra bởi model này sẽ được đưa vào model target để validation và có thể chỉ cần một lần duy nhất.
- Sau khi huấn luyện model target và model draft là model distillation của model target và ta muốn deploy model target này trên hệ thống với speculation decoding sẽ được hoạt động như sau:
- Model draft : Tạo ra bộ K token dựa trên prompt đầu vào.
- Model target : Thực hiện forward 1 lần để validation K token được đề xuất
- Accept hoặc reject : Nếu K token được chấp nhận thì chúng sẽ được trả lại cho user. Nếu không chúng sẽ quay lại token được chấp nhận cuối cùng và thực hiện generate token với model target đến khi dừng.
Với cách này ta đã giảm số lần chạy với model target có kích thước lớn và chi phí đắt đỏ xuống.
- Ưu điểm phương pháp này khi có thể giảm số lần inference với model target kích thước to chậm và tốn kém chi phí. Tuy nhiên, chất lượng phụ thuộc vào model draft. Nếu model draft chất lượng kém sẽ dẫn đến thời gian phản hồi vừa chậm và chi phí lớn.
6. Quantization
Các model LLM hiện nay với kích thước hàng trăm tỷ tham số yêu cầu tài nguyên tính toán và bộ nhớ lớn gây khó khăn trong việc triển khai. Thông thường các weight của model được huấn luyện ở định dạng 32 bit với độ chính xác cao. Tuy nhiên, với định dạng này yêu cầu bộ nhớ lớn khi với mỗi 1B tham số cần đến 4GB VRAM để có thể load model. Do đó, kỹ thuật quantization nén các weight model về các dạng 16 bit, 8 bit hoặc 4 bit giúp giảm kích thước model, tăng tốc quá trình inference mà vẫn duy trì hiệu suất chấp nhận được.
6.1 Lợi ích từ việc lượng tử hóa
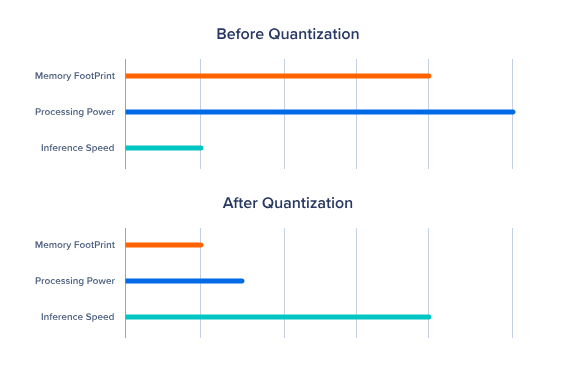
- Kích thước model nhỏ hơn : Lượng tử hóa làm giảm đáng kể dung lượng lưu trữ cần thiết cho model giúp việc lưu trữ và triển khai dễ dàng hơn.
- Giảm mức sử dụng bộ nhớ : Trong quá trình inference các model lượng tử yêu cầu ít bộ nhớ hơn cho phép chúng chạy trên các thiết bị có tài nguyên hạn chế
- Inference nhanh hơn : Các phần cứng như NVIDIA được tối đa hóa cho các phép tính có độ chính xác thấp như 4 bit. Chạy các model được lượng tử trên các thiết bị này giúp tăng tốc độ tính toán về thời gian inference.
6.2 Một số chiến lược lượng tử hóa
Lượng tử hóa tuyến tính : Lượng tử hóa tuyến tính là kỹ thuật tối ưu hóa mô hình học sâu bằng cách chuyển các giá trị trọng số từ dạng dấu phẩy động (float32) về dạng số nguyên có độ chính xác thấp hơn (thường là int8 hoặc FP16) bằng phép ánh xạ tuyến tính, nhờ đó giảm đáng kể kích thước mô hình và chi phí tính toán trong khi vẫn duy trì hiệu năng dự đoán ở mức chấp nhận được. Phương pháp này ánh xạ một dải giá trị trong không gian lưu trữ như FP32 sang tập hợp giá trị trong không gian lưu trữ ít bit hơn như INT8 thông qua bước tỷ lệ (scale) và điểm không (zero‑point), giúp đẩy nhanh tốc độ suy luận trên phần cứng như CPU, GPU, TPU hay NPU, đặc biệt hữu ích khi triển khai trên các thiết bị biên, điện thoại di động hoặc hệ thống nhúng hạn chế tài nguyên. Kết quả là mô hình trở nên nhẹ hơn, tiêu thụ năng lượng thấp hơn mà vẫn đảm bảo độ chính xác gần tương đương, mở ra khả năng ứng dụng rộng rãi trong môi trường thị giác máy tính, xử lý ngôn ngữ, và AI di động.
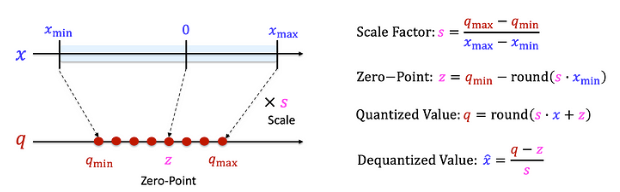
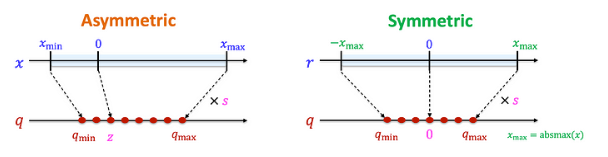
- Lượng tử hóa bất đối xứng : Là kỹ thuật chuyển đổi weight của hoặc activation của model sang không gian lưu trữ ít bit hơn với điểm zero-point không bắt buộc nằm giữa dải giá trị trong không gian mới như lượng tử tuyến tính. Tức là ta sẽ định nghĩa lại phạm vi ánh xạ tuỳ theo giá trị nhỏ nhất và lớn nhất thực tế của dữ liệu. Nhờ vậy toàn bộ dải bit tận dụng được hiệu quả hơn đặc biệt là khi dữ liệu bị lệch về một phía giúp giảm thiểu sai số lượng tử hơn so với lượng tử tuyến tính đối xứng.
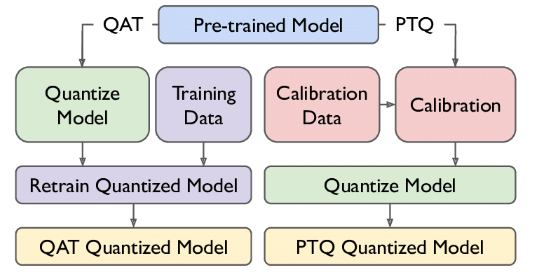
- PTQ : Không cần phải huấn luyện lại model trong khi lượng tử hóa được áp dụng trực tiếp vào các model đã được huấn luyện trước đấy. PTQ phân tích phân phối weight của model xác định các tham số lượng tử hóa và chuyển đổi trọng số sang không gian mới lưu trữ ít bit hơn. Tuy nhanh chóng và dễ dàng nhưng nó có thể làm giảm hiệu suất model.
- QAT : Là kỹ thuật kết hợp chuyển đổi weight vào trong quá trình huấn luyện LLM. Bằng cách mô phỏng độ chính xác thấp hơn trong quá trình huấn luyện, các model có thể học được cách thích ứng với nhiễu lượng tử trong quá trình huấn luyện. Tuy nhiên, phương pháp này đòi hỏi nhiều tính toán và tốn kém kèm với việc suy giảm độ chính xác nếu không có cơ chế xử lý các điểm nhạy cảm của model trong khi huấn luyện như weight gradient.
- Mixed precision quantization : Sử dụng độ chính xác hỗn hợp khác nhau cho các phần khác nhau của model cân bằng giữa hiệu suất và độ chính xác. Phương pháp này đang được sử dụng rộng rãi và đem lại nhiều kết quả kỳ vọng.
Các kỹ thuật lượng tử hóa đem lại nhiều lợi ích như giảm kích thước model và tăng tốc độ inference. Tuy nhiên, quá trình lượng tử hóa này tiềm ẩn nhiều thách thức như suy giảm độ chính xác ảnh hưởng đến kết quả của model và độ phức tạp trong quá trình triển khai yêu cầu người thực hiện phải có hiểu biết chuyên sâu về các kỹ thuật và đặc điểm của model.
Kết luận
Việc triển khai các mô hình LLM trong môi trường thực tế đặt ra nhiều thách thức toàn diện, không chỉ ở khía cạnh kỹ thuật mà còn liên quan đến bài toán vận hành và tối ưu tài nguyên. Trong bối cảnh quy mô dữ liệu ngày càng mở rộng cùng với kỳ vọng cao từ phía người dùng, các yêu cầu về độ trễ thấp, khả năng mở rộng linh hoạt và chi phí vận hành hợp lý trở nên ngày càng cấp thiết. Do đó, để xây dựng các hệ thống phục vụ LLM hiệu quả, cần có sự phối hợp chặt chẽ và linh hoạt giữa nhiều kỹ thuật tối ưu, nhằm vừa đáp ứng tốt nhu cầu người dùng, vừa đảm bảo hiệu quả về mặt chi phí và hiệu năng trong dài hạn.
