Kiến trúc Transformer đã trở thành nền tảng trong NLP và đạt được các thành tựu to lớn. Trong Transformer bản chất không tuần tự của nó khiến cho việc mã hóa các thông tin về thứ tự trở thành 1 thách thức lớn. Ở trong Vanilla Transformer phát triển ban đầu sử dụng absolute position embedding, sau đó nó đã được phát triển đến sử dụng relative position embedding. Position embedding đã thêm biểu diễn vị trí của mỗi token vào trong chuỗi giúp cho model transformer có khả năng phân biệt được các vị trí của các token khác. Ở bài viết này, chúng ta sẽ tìm hiểu tổng quan về position embedding.
I. Absolute Position Embedding
Khi ta đọc 1 câu, mỗi từ phụ thuộc vào xung quanh nó. Ví dụ với từ “plant” trong tiếng anh lúc có nghĩa là cây, lúc có nghĩa là nhà máy. Do đó, mô hình cần phải hiểu được các biến thể này dựa vào từ này với các từ xung quanh để tạo nên ngữ cảnh.
Khi mã hóa, vị trí của mỗi token sẽ được thêm vào trong vector embedding. Đây là vector đại diện cho vị trí của token đó trong chuỗi. Đây là vector đại diện cho giá trị của token trong chuỗi câu đó. Điều này giúp cho mô hình hiểu được thứ tự các từ và mối quan hệ giữa các từ trong câu, cho phép nó phân biệt được các nghĩa khác nhau dựa vào các ngữ cảnh xung quanh.
Khi mã hóa sẽ không phụ thuộc vào vị trí của các token khác trong chuỗi. Điều này có nghĩa ta không quan tâm đến mối quan hệ ở timestep này với các timestep khác.
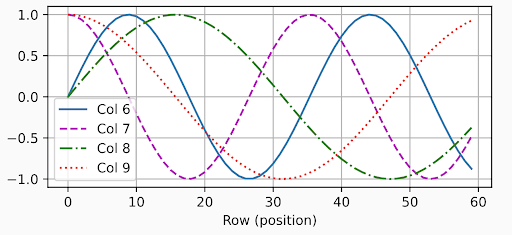
Mỗi vị trí trong chuỗi sẽ được gán bởi một vector biểu diễn riêng biệt thường dựa trên hàm sin và cos với tần số khác nhau.
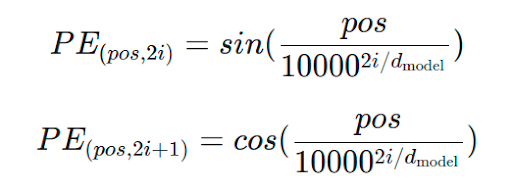
Ưu điểm:
+Dễ triển khai, cung cấp thông tin thứ tự của các token trong câu, bổ sung thông tin ngữ cảnh của các từ và vị trí của chúng.
Nhược điểm:
+ Absolute position embedding chỉ ghi nhớ các vector ở vị trí đó mà không cung cấp thông tin về vị trí tương đối vì các vector ở trong absolute position embedding là độc lập với nhau, không có mối liên kết nào. Điều này dẫn đến vị trí 1 và 2 sẽ trông giống như vị trí 1 và 10.
+ Gặp khó khăn trong việc dự đoán token các vị trí mà chúng không được thấy trong quá trình huấn luyện và bị giới hạn bởi max_length_token trong quá trình huấn luyện.
Ví dụ ta các câu đầu vào có 3 token [“I”, “love”, “python”] , dimension = 4
Sau khi chuyển thành các vector embedding có các giá trị:
“I” : [0.1,0.2,0.3,0.4]
“love” : [0.5,0.6,0.7,0.8]
“python” : [0.9,1.0,1.1,1.2]
Ta tính position embedding cho chúng như sau:
Với token “I” ta sử dụng hàm sin cho vị trí chẵn 0, 2 và hàm cos cho vị trí lẻ 1,3 và thu được vector cho position embedding : [0,1,0,1]
Tương tự với token “love” ta thu được vector : [0.841,0.540,0.0998,0.995]
Tương tự với token “python” : [0.909,−0.416,0.1987,0.9801]
Sau đó, ta cộng vector embedding và position embedding để tạo ra được embedding cuối cùng cho mỗi token đó thu được:
“I” : [0.1,1.2,0.3,1.4]
“love” : [1.341,1.14,0.7998,1.795]
“python” : [1.809,0.584,1.2987,2.1801]
II. Relative Position embedding
Thay vì mỗi token trong chuỗi được gán cho 1 số cố định thì mã hóa tương vị trí tương đối tính toán sự khác biệt về vị trí giữa các từ trong chuỗi tức là mối quan hệ tương đối giữa các vị trí. Ví dụ với 2 token ở vị trí i và j trong câu thì nó không quan tâm đến vị trí tuyệt đối mà chỉ quan tâm đến khoảng cách khác biệt giữa vị trí i và và j.
Vì relative position embedding được tính toán giữa 2 vector, chúng ta không thể thêm trực tiếp vào trong vector token embedding. Thay vào đó, nó sẽ được thêm vào trực tiếp attention score. Kỹ thuật này nó sẽ chèn vị trí tương đối ở trong lớp Attention để tính toán sự tương tác giữa chúng thay vì sử dụng các vị trí tuyệt đối của các từ trong quá trình toán toán Attention. Cụ thể :
Đầu tiên ta có ma trận biểu diễn khoảng cách giữa các token này.

Chúng ta tính toán ma trận attention với khoảng cách tương đối giữa các token:
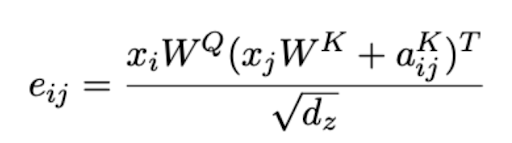
Ưu điểm:
+ Relative Position Embedding giúp mô hình xử lý chuỗi dài hiệu quả hơn, vì không bị ràng buộc bởi các vị trí tuyệt đối cố định.
Tăng cường tổng quát hóa giúp mô hình có thể học các mối quan hệ giữa các phần tử một cách linh hoạt hơn.
Nhược điểm:
+ Do relative position embedding thêm thông tin mới cần được đưa vào hai điểm trong quá trình tính toán attention nên nó cũng gây ra sự chậm trễ trong cả huấn luyện và inference.
+ Khi ta thêm 1 token mới, chúng ta cần phải tính toán lại các cặp key-value mới tức không thể tận dụng KV-Cache
III. Rotary Position Embedding
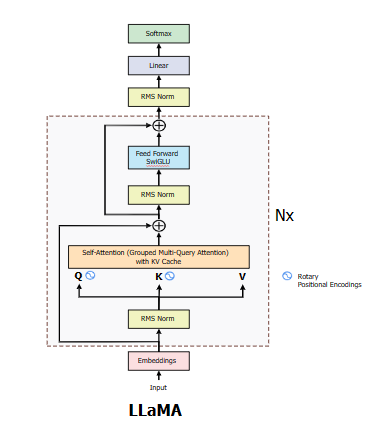
Ý tưởng ở đây là thay vì thêm vị trí của token vào vector embedding thì ta duy trì 1 vector quay cho nó. Nếu 1 token ở xa thì nó sẽ quay 1 số lần góc theta với số lần đó biểu thị vị trí trong câu.
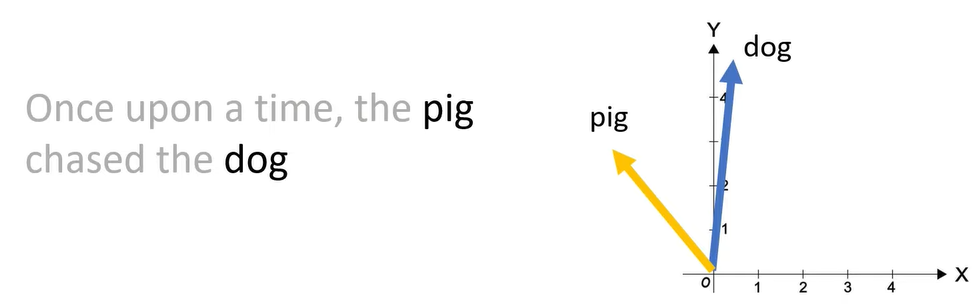
Khi chúng ta thêm các token vào đầu hoặc cuối thì góc giữa 2 token vẫn được giữa nguyên.

Rotary position embedding có cả 2 ưu điểm của absolute position embedding và relative position embedding.
Với dạng 2D công thức tổng quát như sau với ma trận đầu tiên là áp dụng phép quay:
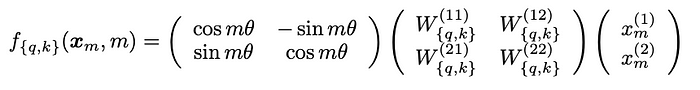
Với trường hợp tổng quát có n chiều thì ma trận quay chúng ta có dạng:
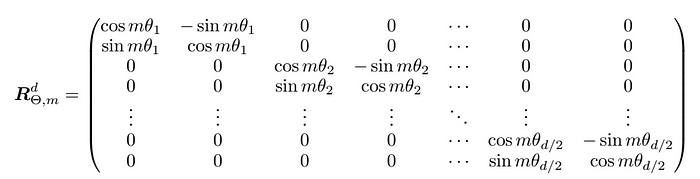
Do ma trận quay ta áp dụng cho dạng 2D. Do đó, trong quá trình tính toán chúng ta chia vector thành các nhóm gồm 2 chiều kề nhau làm 1 nhóm sau đó áp dụng vector quay.
Kết luận
Absolute position embedding không khái quát hóa các trường hợp mà vượt qua độ dài huấn luyện của chuỗi. Tuy nhiên, vì tính đơn giản và đạt kết quả tốt nên vẫn được sử dụng
Relative position embedding giúp cho model khái quát hóa các trường hợp độ dài lớn hơn so với huấn luyện nhưng khiến chúng không thể lưu trữ các giá trị KV trong cache làm quá trình training và inference bị chậm
RoPE phức tạp tuy nhiên lại hội tụ nhanh và khái quát thành các chuỗi dài. Hiện nay nó đang được áp dụng cho LLaMA và đạt được kết quả rất tốt.
Xem thêm bài viết về Big Data