
Model DeepSeek đã trải qua các phiên bản từ DeepSeekMoE đến DeepSeek-V2, DeepSeek-V3 và hiện tại đang là phiên bản DeepSeek-R1 đang đạt được hiệu suất vượt trội trong suy luận. Các kiến trúc của DeepSeek đều dựa trên kiến trúc MoE. Vậy DeepSeek-R1 đã được huấn luyện như nào?
1. Giới thiệu
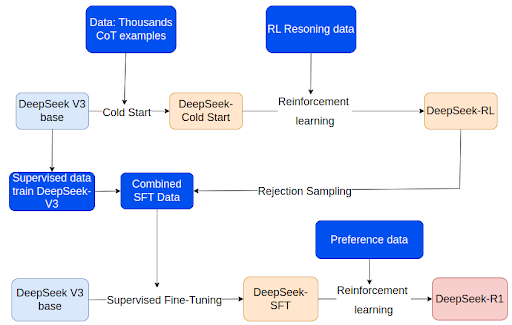
Với phiên bản DeepSeek-V3, mô hình yêu cầu dữ liệu có giám sát để SFT bao gồm dữ liệu lý luận và phi lý luận để đảm bảo mô hình có khả năng trả lời các câu hỏi cơ bản và nó yêu cầu một lượng dữ liệu lớn để có thể mang lại hiệu suất.
DeepSeek-R1-Zero bỏ qua bước SFT với dữ liệu giám sát và áp dụng trực tiếp học tăng cường (RL) vào model để tự tiến hóa thông qua quá trình continuous learning. Và điều này cho phép mô hình học được lý luận.

Reward model của DeepSeek-R1-Zero được sử dụng dựa trên luật mà không sử dụng reward model để đưa ra điểm thưởng cho các câu trả lời như các thuật toán thường sử dụng. Phần thưởng này được chia ra thành 2 loại với phần thưởng cho câu trả lời chính xác và với format đúng định dạng mẫu.
Sau quá trình huấn luyện GRPO, họ thấy DeepSeek-R1-Zero sở hữu khả năng xác thực, phản ánh và tạo ra các CoT dài. Mô hình có thể tự động phát triển các kỹ năng lý luận chỉ bằng RL mà không cần dữ liệu có giám sát đã có chú thích để dạy nó đưa ra câu trả lời đúng. Ngoài ra, khi số lần lặp các bước RL tăng lên, mô hình tự động bắt đầu xem xét lại các câu trả lời, phản ánh và khám phá các giải pháp khả thi khác giúp tăng cường khả năng suy luận của mô hình.
Tuy nhiên, DeepSeek-R1-Zero gặp một số hạn chế về vấn đề đọc kém và pha trộn ngôn ngữ, do đó họ đã giới thiệu DeepSeek-R1 để cải thiện điều này. Quá trình huấn luyện của DeepSeek-R1 với RL gồm 2 lần với lần đầu tiên để giúp mô hình suy luận và lần thứ 2 để điều chỉnh theo sở thích của con người. Cùng với đó cũng có 2 lần huấn luyện SFT với lần đầu để rèn luyện khả năng suy luận mô hình cơ bản và lần còn lại để rèn khả năng không suy luận.
2. Thuật toán Reinforcement learning
Trong DeepSeek, họ đề xuất thuật toán Group Relative Policy Optimization (GRPO) là một phương pháp để học tăng cường. GRPO giúp mô hình học tốt hơn bằng cách so sánh các hành động khác nhau và thực hiện các bản cập nhật nhỏ có kiểm soát thông qua một nhóm các quan sát khác nhau. Nó loại bỏ nhu cầu về model critic riêng biệt dựa trên điểm số của nhóm để ước tính lợi thế cho việc tối ưu hóa policy.

- GRPO so sánh các hành động trong 1 nhóm làm giảm sự thay đổi các bản cập nhật của policy giúp việc học ổn định hơn.
- Cập nhật có kiểm soát : Ràng buộc KL ngăn chặn những sự thay đổi lớn gây mất ổn định đối với policy
- GRPO giúp tránh việc phải đánh giá mọi hành động có thể xảy ra giúp tăng hiệu quả tính toán.
GRPO tương tự với PPO tuy nhiên nó không có model critic như PPO và nó sử dụng lấy mẫu theo nhóm cho mỗi đầu vào tập trung cho hiệu suất tương đối trong nhóm thay vì tuyệt đối.
3. Cold Start
- Giai đoạn đầu tiên trong pipeline huấn luyện DeepSeek-R1 đóng vai trò trong việc giải quyết những thách thức mà DeepSeek-R1-Zero gặp phải. Tại giai đoạn này huấn luyện SFT model giúp cải thiện khả năng đọc và hiệu suất đầu ra để chuẩn bị qua quá trình huấn luyện RL đầu tiên.
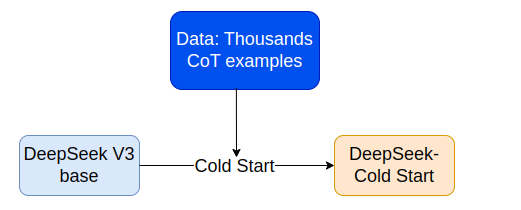
- Để tạo ra một tập dữ liệu cho quá trình huấn luyện Cold Start, các tác giả đã tiếp cận theo các phương pháp khác nhau:
- Sử dụng few-shot : Model base được đưa ra prompt với CoT dài. Ví dụ cung cấp một giải pháp bao gồm nhiều bước cho các vấn đề phức tạp như toán học.
- Model base sử dụng prompt trực tiếp để tạo ra các câu trả lời chi tiết bao gồm các phản ánh và xác minh các giải pháp của nó.
- Tái sử dụng output của DeepSeek-R1-Zero: Các output có thể đọc được từ DeepSeek-R1-Zero đã được chọn lọc và tinh chỉnh.
- Thiết kế định dạng đầu ra: Để tăng khả năng đọc, tác giả đã thiết kế một định dạng đầu ra có cấu trúc cho model.
- Lợi ích của phương pháp này so với DeepSeek-R1-Zero:
- Giúp cải thiện khả năng đọc khi chỉ định format.
- Giúp mô hình khái quát tốt hơn trong các nhiệm vụ lý luận phức tạp
- Tăng cường hiệu suất cho model bằng dữ liệu có cấu trúc và với kinh nghiệm của con người.
4. Huấn luyện RL hướng lý luận
Sau quá trình Cold Start mô hình tiếp tục huấn luyện với RL dựa trên chính dữ liệu Cold Start, đặc biệt là đối với các nhiệm vụ về code, toán học, khoa học và lý luận logic. Trong quá trình này, người ta quan sát thấy model gây ra sự nhầm lẫn ngôn ngữ do đó đã có một reward model cụ thể đã được thiết lập để giải quyết vấn đề lẫn lộn ngôn ngữ.
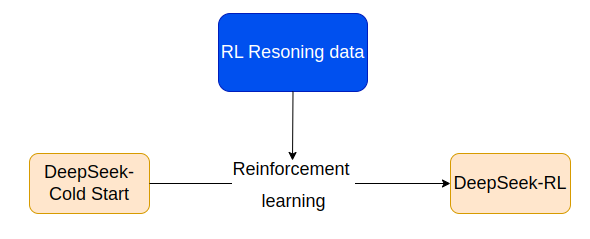
Quá trình huấn luyện
- Phần thưởng cho độ chính xác : Hệ thống phần thưởng được thiết kế để đảm bảo mô hình đưa ra câu trả lời đúng cho các vấn đề được xác định rõ ràng.
- Giảm thiểu sự pha trộn ngôn ngữ : Vấn đề thường gặp khi huấn luyện RL là không nhất quán về ngôn ngữ trong đầu ra của CoT khi prompt liên quan đến nhiều ngôn ngữ. Giải pháp đưa ra là tác giả đã giới thiệu phần thưởng về tính nhất quán của ngôn ngữ được tính theo tỷ lệ các từ trong ngôn ngữ đích của CoT.
- Quá trình huấn luyện được thực hiện tiếp tục cho đến khi mô hình hội tụ cho thấy hiệu suất ổn định và đáng tin cậy trong các nhiệm vụ.
Kết quả sau quá trình RL đã giúp model đạt hiệu suất mạnh mẽ trên các bộ dữ liệu MATH-500 hay AIME 2024. Cùng với đó model cho thấy khả năng suy luận mạnh mẽ, đưa ra kết quả mạch lạc.
5. Rejection sampling và SFT
Mục tiêu của quá trình này giúp cải thiện khả năng suy luận của model bằng cách lựa chọn và tinh chỉnh các đầu ra inference tốt. Mở rộng khả năng chung phi lý luận như viết, nhập vai, dịch thuật. Cuối cùng là cải thiện tính nhất quán của phản hồi, lọc ra các đầu ra hỗn loạn nhằm đảm bảo rằng model tạo ra các phản hồi dễ đọc và nhất quán về mặt logic.
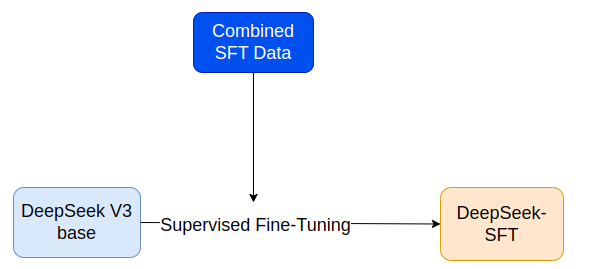
Xử lý dữ liệu lý luận:
- Rejection sampling : Sau khi huấn luyện RL, đầu ra của model có thể bao gồm nội dung không phù hợp. Do đó, họ sử dụng rejection sampling để chọn dữ liệu hợp lệ từ model đã huấn luyện. Dữ liệu này sau đó được sử dụng cho model SFT.
- Ở giai đoạn này, họ mở rộng tập dữ liệu bằng cách đưa vào dữ liệu từ các miền khác,
- Vì đầu ra của model đôi khi có thể gây nhầm lẫn hoặc khó hiểu nên họ đã tiến hành làm sạch dữ liệu bằng cách lọc ra các đầu ra ngôn ngữ phù hợp, các đoạn văn quá dài và CoT chứa code. Đối với mỗi nhiệm vụ lý luận, nhiều phản hồi được lấy mẫu và chỉ giữa lại các câu trả lời đúng. Cuối cùng, thu thập được khoảng 600K mẫu huấn luyện liên quan đến lý luận
Dữ liệu phi lý luận
Dữ liệu bao gồm các nhiệm vụ như viết, QA, dịch thuật,… Đối với các nhiệm vụ này, họ sử dụng pipeline DeepSeek-V3 và tái sử dụng một số tập dữ liệu SFT đã được thu thập trong DeepSeek-V3. Đối với một số nhiệm vụ phi lý luận, họ gọi DeepSeek-V3 để tạo CoT tiềm năng nhằm cung cấp các quy trình lý luận tốt hơn khi trả lời câu hỏi. Cuối cùng tạo ra được 200K mẫu phi lý luận để huấn luyện.

6. RL cho ngữ cảnh
Giai đoạn này tập trung vào việc tinh chỉnh DeepSeek-R1 để xử lý tất cả các nhiệm vụ lý chuận và mục đích chung theo sở thích của con người đảm bảo mô hình cung cấp phản hồi hữu ích, vô hại và hiệu quả.
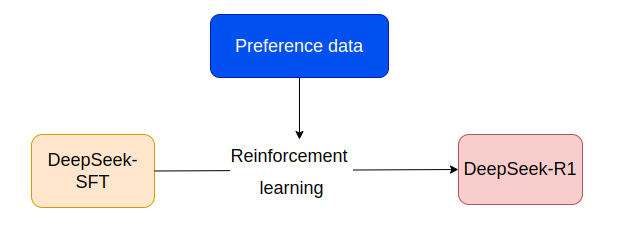
Mục tiêu chính là cải tiến DeepSeek-R1 trở nên linh hoạt và mạnh mẽ hơn có các khả năng thực hiện các nhiệm vụ đòi hỏi tư duy cao như toán học, logic, lập trình. Đồng thời xử lý tốt các nhiệm vụ như viết sáng tạo, trả lời các câu hỏi phù hợp với sở thích của người dùng.
Quá trình huấn luyện được thực hiện:
- Dữ liệu lý luận : Sử dụng reward model theo quy tắc cho các nhiệm vụ lý luận. Những phần thưởng này tập trung vào tính chính xác và mạch lạc trong việc giải quyết các nhiệm vụ
- Dữ liệu chung: Reward model được sử dụng dựa trên sở thích giống con người đánh giá phản hồi theo tính hữu ích, dễ đọc và vô hại
Sau quá trình này hiệu suất nhiệm vụ được cải thiện trên các thang đo điểm chuẩn, phù hợp với kỳ vọng của người dùng, thân thiện với người dùng
7. Distillation
Các model lớn như DeepSeek-R1 tốn kém về mặt tài nguyên tính toán và cần nhiều tài nguyên để inference. Việc chắt lọc kiến thức mô hình lớn cho các model nhỏ hơn giúp chúng nhanh hơn, nhẹ hơn và có thể triển khai trên các thiết bị phần cứng hạn chế.
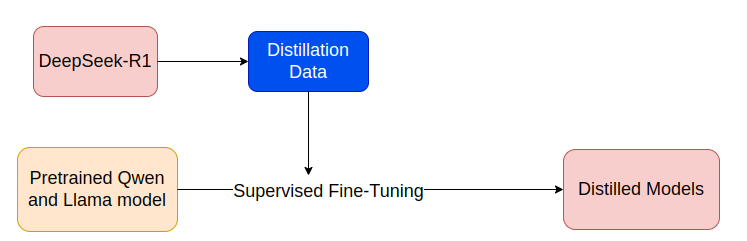
- Trong DeepSeek-R1 họ đã chắt lọc khả năng suy luận của DeepSeek-R1 thành các model có kích thước nhỏ hơn như các model Qwen 7B đến 32B và LLama từ 7B đến 13B.
- Dữ liệu được dùng để huấn luyện các model nhỏ hơn bao gồm khoảng 800K mẫu lý luận và phi lý luận khác nhau.
- Kiến thức từ DeepSeek-R1 được chuyển giao cho các model nhỏ hơn bằng cách sử dụng học giám sát và reward-guided distillation
Các model này sau quá trình huấn luyện đã vượt trội hơn các model base ở khả năng lý luận và có hiệu suất hơn các model o1-mini của OpenAI.
8. Kết luận
DeepSeek đã đạt được những thành công khi đạt được hiệu suất cao ở các thang điểm chuẩn và ở khả năng lý luận của mô hình. Nó mở ra cơ hội canh tranh với OpenAI, cung cấp các giải pháp AI có thể mở rộng các model nhỏ hơn mà không ảnh hưởng đến chất lượng. Tuy nhiên, DeepSeek vẫn còn những hạn chế về mặt ngôn ngữ khi tập trung chủ yếu vào tiếng Anh và tiếng Trung.