
Trong thời đại dữ liệu bùng nổ, lượng thông tin phi cấu trúc như email, bài đăng mạng xã hội, hình ảnh hay video đang chiếm tới hơn 80% tổng dữ liệu toàn cầu. Việc lưu trữ, tìm kiếm và khai thác hiệu quả khối dữ liệu khổng lồ này trở thành một thách thức lớn, đặc biệt khi các doanh nghiệp muốn áp dụng trí tuệ nhân tạo để tạo giá trị. Đây chính là lý do các vector database ra đời. Khác với cơ sở dữ liệu truyền thống, vector database được thiết kế chuyên biệt để xử lý dữ liệu dưới dạng vector nhiều chiều – dạng biểu diễn tối ưu cho các mô hình AI, đặc biệt trong xử lý ngôn ngữ tự nhiên, thị giác máy tính và hệ thống gợi ý. Chúng không chỉ giúp tăng tốc tìm kiếm theo ngữ nghĩa mà còn mở ra khả năng ứng dụng AI ở quy mô lớn, chính xác và giàu ngữ cảnh hơn bao giờ hết.
Vector Database là gì?
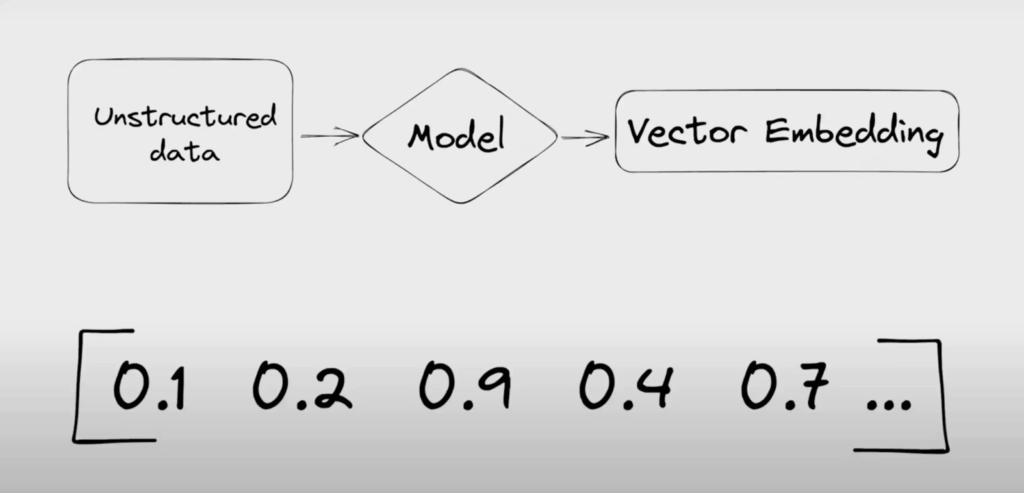
Vector database là một loại cơ sở dữ liệu được xây dựng để lưu trữ, quản lý và truy vấn các vector – những dãy số nhiều chiều mô tả đặc trưng của dữ liệu. Các vector này thường được tạo ra bởi các mô hình AI hoặc thuật toán học máy, gọi là embedding models, nhằm chuyển đổi dữ liệu gốc (văn bản, hình ảnh, âm thanh) thành một biểu diễn số học mà máy tính có thể xử lý và so sánh được.
Ưu điểm cốt lõi của vector database nằm ở khả năng tìm kiếm theo độ tương tự (similarity search) một cách nhanh chóng và chính xác. Thay vì tìm kiếm dựa trên từ khóa chính xác như hệ thống truyền thống, vector database tìm các mục dữ liệu “gần” nhau về mặt ngữ nghĩa hoặc đặc trưng hình ảnh. Điều này đặc biệt hữu ích trong các lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), thị giác máy tính (Computer Vision), và hệ thống khuyến nghị (Recommendation Systems).
Cơ chế hoạt động của Vector Database
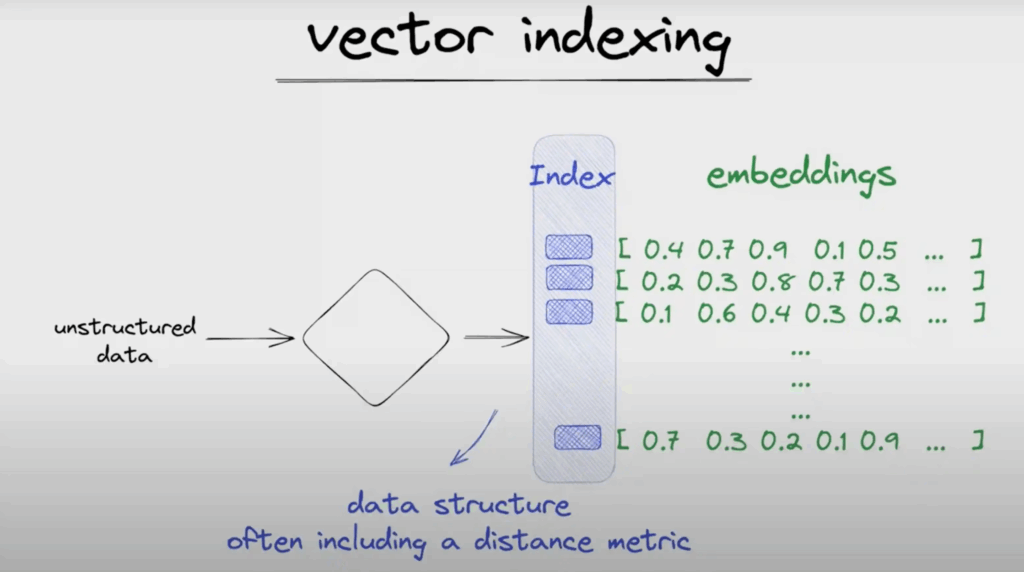
Vector database hoạt động bằng cách lưu trữ và quản lý các high-dimensional vector data, thường được tạo ra từ các mô hình học máy. Khi một vector truy vấn được nhập vào, hệ thống sẽ tính toán độ tương đồng hoặc khoảng cách giữa vector này và các vector đã lưu, sử dụng nhiều thước đo khác nhau như cosine similarity hoặc Euclidean distance.
Quy trình này dựa trên các kỹ thuật lập chỉ mục tiên tiến để nhanh chóng truy xuất các vector gần nhất, đảm bảo khả năng tìm kiếm hiệu quả và mở rộng quy mô. Nhờ đó, vector database trở thành một hệ thống tối ưu cao cho các tác vụ như tìm kiếm theo độ tương tự (similarity search), hệ thống gợi ý (recommendation engines) và phân tích dữ liệu theo thời gian thực, cho phép ứng dụng xử lý hiệu quả khối lượng dữ liệu lớn, nhiều chiều.
1. Kỹ thuật lưu trữ
Để xử lý sự phức tạp và khối lượng lớn của dữ liệu nhiều chiều, vector database sử dụng nhiều phương pháp lưu trữ khác nhau:
- Sharding: Chia dữ liệu thành các phần nhỏ và phân phối lên nhiều máy chủ để tăng hiệu suất và khả năng mở rộng.
- Partitioning: Tách dữ liệu thành các phân vùng dựa trên tiêu chí nhất định, giúp truy cập và quản lý dữ liệu hiệu quả hơn.
- Caching: Lưu trữ tạm thời dữ liệu thường xuyên được truy cập trong bộ nhớ để rút ngắn thời gian phản hồi.
- Replication: Tạo nhiều bản sao dữ liệu trên các máy chủ khác nhau để đảm bảo tính sẵn sàng và độ tin cậy.
2. Phương pháp tìm kiếm
Các phương pháp tìm kiếm trong vector database thường được phân loại như sau:
- Similarity Search: Tính toán khoảng cách hoặc độ tương đồng giữa vector truy vấn và các vector đã lưu, sau đó trả về các vector gần nhất.
- Semantic Search: Hiểu ý nghĩa và ngữ cảnh của truy vấn, rồi khớp nó với các tài liệu hoặc dữ liệu liên quan dựa trên nội dung ngữ nghĩa.
- Nearest Neighbor Search (NNS): Tìm các điểm dữ liệu gần nhất trong không gian nhiều chiều.
- Approximate Nearest Neighbor Search (ANNS): Sử dụng thuật toán để tìm kiếm nhanh các điểm gần đúng, chấp nhận hy sinh một phần độ chính xác để tăng tốc độ.
3. Các thuật toán phổ biến
- KD-tree: Cấu trúc dữ liệu dạng cây dùng để tổ chức các điểm trong không gian k chiều.
- Ball-tree: Tương tự KD-tree nhưng hiệu quả hơn cho dữ liệu nhiều chiều.
- Locality Sensitive Hashing (LSH): Kỹ thuật băm đảm bảo các phần tử giống nhau được đưa vào cùng một “bucket”.
- Hierarchical Navigable Small World (HNSW): Cấu trúc đồ thị giúp tìm kiếm hiệu quả nhờ đặc tính “small-world”.
4. Các phương pháp dựa trên lượng tử hóa (Quantization-Based Approaches)
Để lưu trữ và truy xuất vector nhiều chiều một cách hiệu quả, các phương pháp lượng tử hóa như Product Quantization (PQ) và các biến thể của nó được áp dụng. Những kỹ thuật này nén vector thành dạng biểu diễn nhỏ gọn hơn, giảm yêu cầu lưu trữ và tăng tốc độ truy xuất.
Ứng dụng của Vector Database
Nhờ khả năng tìm kiếm theo ngữ nghĩa và xử lý dữ liệu phi cấu trúc, vector database được ứng dụng trong nhiều lĩnh vực khác nhau.
Trong xử lý ngôn ngữ tự nhiên (NLP), chúng giúp các hệ thống chatbot, công cụ tìm kiếm và trợ lý ảo hiểu được ý định thực sự của người dùng, từ đó trả về kết quả phù hợp hơn thay vì chỉ khớp từ khóa. Trong thị giác máy tính (Computer Vision), vector database cho phép tìm kiếm hình ảnh hoặc nhận dạng vật thể bằng cách so sánh embedding hình ảnh, hữu ích cho nhận diện khuôn mặt, tìm kiếm sản phẩm bằng ảnh, hoặc phân loại nội dung.
Ở lĩnh vực hệ thống gợi ý (Recommendation Systems), chúng phân tích hành vi và sở thích của người dùng (đã được mã hóa thành vector) để đưa ra các đề xuất cá nhân hóa. Trong ứng dụng AI hỗ trợ mô hình ngôn ngữ lớn (LLMs), vector database đóng vai trò như bộ nhớ dài hạn, lưu trữ thông tin để phục vụ truy vấn ngữ nghĩa và cải thiện chất lượng phản hồi của mô hình.
Ngoài ra, vector database còn hỗ trợ kiểm duyệt nội dung (Content Moderation), cho phép tự động phát hiện các nội dung nhạy cảm hoặc vi phạm bằng cách so sánh embedding với dữ liệu mẫu đã được gắn nhãn. Tốc độ xử lý gần như thời gian thực giúp giảm thiểu rủi ro và nâng cao trải nghiệm người dùng.
Kết luận
Vector database không chỉ là một công cụ lưu trữ, mà là nền tảng cốt lõi để AI có thể hiểu, tìm kiếm và khai thác dữ liệu phi cấu trúc ở quy mô lớn. Từ việc tăng tốc truy vấn ngữ nghĩa cho LLM, cải thiện độ chính xác của hệ thống gợi ý, đến việc hỗ trợ kiểm duyệt nội dung, chúng đóng vai trò quan trọng trong việc đưa AI từ lý thuyết đến ứng dụng thực tế. Khi nhu cầu xử lý dữ liệu thông minh ngày càng cao, vector database sẽ tiếp tục là một mảnh ghép chiến lược trong hạ tầng AI hiện đại.


